
Gracias a los últimos avances en procesamiento del lenguaje natural, el motor de búsqueda de literatura científica Semantic Scholar ahora incluye un nuevo modelo de inteligencia artificial que ofrece un breve extracto sobre cada artículo científico para ayudar a los investigadores en su día a día
La noticia: un nuevo modelo de inteligencia artificial (IA) capaz de resumir la literatura científica puede ayudar a los investigadores a revisar e identificar los últimos artículos más innovadores que desean leer. El 16 de noviembre, el Instituto Allen de Inteligencia Artificial (AI2) implementó el modelo en su producto estrella, Semantic Scholar, el motor de búsqueda de artículos científicos impulsado por inteligencia artificial.
El sistema ofrece un resumen de una frase junto al famoso indicador TLDR (too long; didn’t read en inglés, demasiado largo; no leído) que aparece debajo de cada artículo de ciencias de la computación (por ahora) cuando los usuarios utilizan la función de búsqueda o van a la página de un autor. El trabajo también fue bien recibido cuando se presentó en la reciente conferencia Empirical Methods for Natural Language Processing.
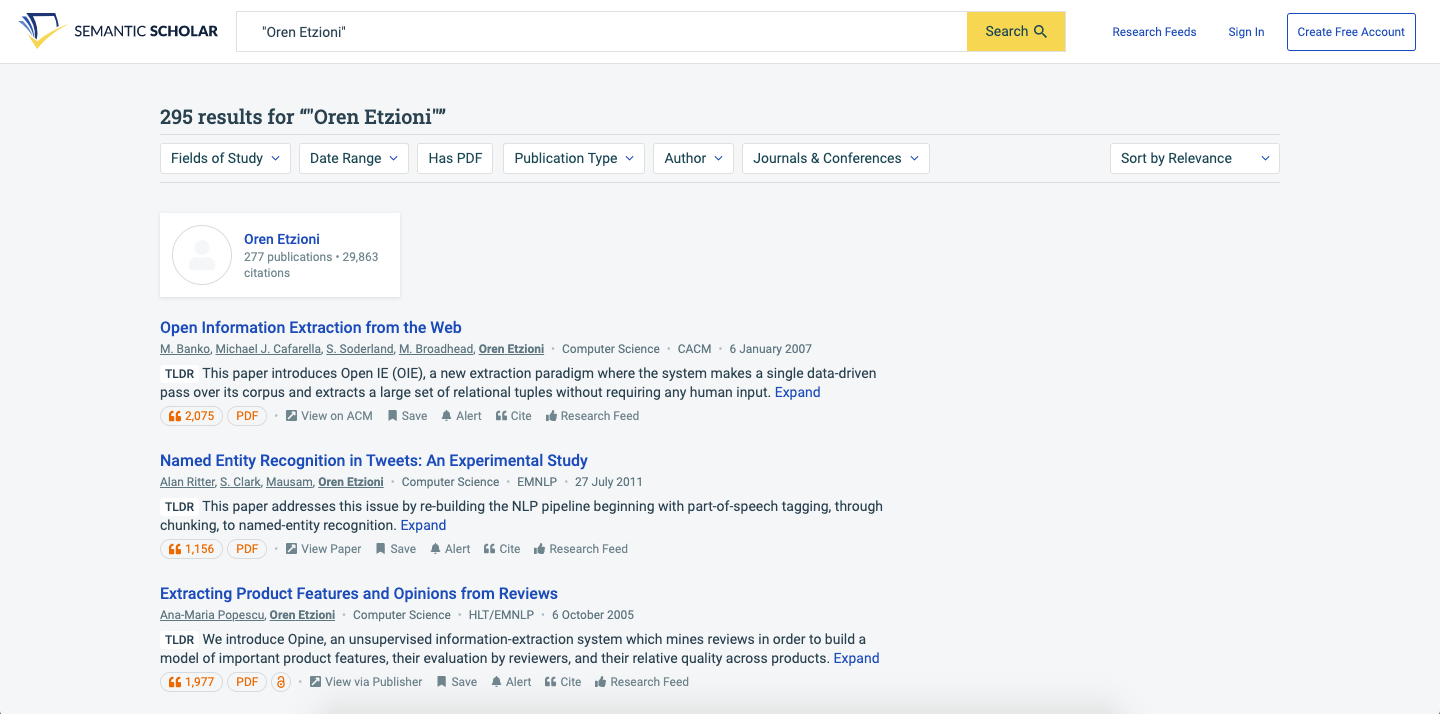
Foto: Una captura de pantalla de la función TLDR en Semantic Scholar. Créditos: AI2
El contexto: en esta era de sobrecarga de información, el uso de inteligencia artificial para resumir texto ha sido un problema común en el área del procesamiento del lenguaje natural (PLN). Hay dos enfoques generales para llevar a cabo esta tarea. Uno se llama "extractivo", que busca encontrar una frase o un conjunto de frases del texto que capture su esencia. El otro se llama "abstractivo", que implica generar nuevas frases. Si bien las técnicas extractivas solían ser más populares debido a las limitaciones de los sistemas de PLN, los avances de los últimos años en la generación del lenguaje natural han hecho que ahora el método abstractivo resulte mucho mejor.
Cómo lo hicieron: el modelo abstractivo de AI2 utiliza lo que se conoce como transformador, un tipo de arquitectura de red neuronal inventada en 2017 y que, desde entonces, ha impulsado todos los avances importantes en el PLN, incluido el GPT-3 de OpenAI. Los investigadores primero entrenaron al transformador en un corpus genérico de texto para formar su conocimiento básico del inglés. Este proceso se conoce como prentrenamiento y es parte de lo que hace que los transformadores sean tan potentes. Luego, reajustaron el modelo, en otras palabras, lo entrenaron en la tarea específica de crear un resumen.
Los datos del reajuste: los investigadores primero crearon un conjunto de datos llamado SciTldr, con aproximadamente 5.400 parejas de artículos científicos y sus correspondientes resúmenes de una sola frase. Para encontrar resúmenes de alta calidad, los buscaron primero en la plataforma pública de presentación de artículos de conferencias OpenReview, donde los investigadores a menudo publican su propia sinopsis de una frase de su artículo. Esto proporcionó un par de miles de parejas. Luego, los investigadores contrataron a unos anotadores para resumir otros artículos leyendo y condensando aún más los resúmenes que ya habían sido escritos después de la revisión por pares.
Para complementar todavía más estas 5.400 parejas, los investigadores reunieron un segundo conjunto de datos de 20.000 parejas de artículos científicos y sus títulos. Consideraron que como los títulos en sí mismos son una forma de resumen, ayudarían aún más al modelo a mejorar sus resultados. Algo que se confirmó en sus experimentos.
Foto: La función TLDR resulta especialmente útil para hojear artículos en dispositivos móviles. Créditos: AI2
Resumen extremo: si bien muchos otros esfuerzos de investigación han abordado la tarea de crear resúmenes, este destaca por el nivel de compresión lograda. Los artículos científicos incluidos en el conjunto de datos de SciTldr tienen una media de 5.000 palabras. Sus resúmenes de una frase tienen una media de 21 palabras. Esto significa que cada artículo se comprime de media unas 238 veces frente a su tamaño original. El siguiente mejor método abstractivo está entrenado para comprimir artículos científicos en una media de solo 36,5 veces. Durante las pruebas, los revisores humanos también concluyeron que los resúmenes de este nuevo modelo eran más informativos y precisos que los métodos anteriores.
Próximos pasos: el profesor de la Universidad de Washington (EE. UU.) y director del grupo de investigación Semantic Scholar, Daniel Weld, afirma que AI2 ya está trabajando de varias formas de mejorar su modelo a corto plazo. Por un lado, planean entrenar el modelo para resumir no solo con los artículos de ciencias de la computación. Por otro lado, quizás en parte debido al proceso de entrenamiento, han descubierto que los resúmenes TLDR a veces coinciden demasiado con el título del artículo, y eso reduce su utilidad general. Planean actualizar el proceso de entrenamiento del modelo para penalizar esa superposición para que el modelo aprenda a evitar la repetición con el tiempo.
A largo plazo, el equipo también trabajará en resumir varios documentos a la vez, lo que podría ser útil para los investigadores que entran en un nuevo campo o tal vez incluso para los formuladores de políticas que quieren ponerse al día rápidamente. Weld concluye: "Lo que realmente nos gustaría hacer es crear informes de investigación personalizados, donde podríamos resumir no solo un artículo, sino un conjunto de seis avances recientes en una área concreta".
Inteligencia Artificial
La inteligencia artificial y los robots están transformando nuestra forma de trabajar y nuestro estilo de vida.
-
Operator de OpenAI marca el camino de los agentes de IA al tomar decisiones autónomas
El anuncio despeja uno de los dos rumores que han estado circulando por internet. El otro gira en torno a la posible llegada de una superinteligencia

-
OpenAI ha multiplicado casi por siete su inversión de 'lobby' ante la llegada de Trump
La empresa de Sam Altman aumenta su gasto en lobistas para influir en la política y definir el rumbo de la regulación de la IA

-
Minería paralela de datos, la técnica del nuevo traductor de Meta para dominar más de 100 idiomas
La aplicación presentada por Meta nos acerca a la creación de un dispositivo de traducción universal similar al Pez de Babel de La guía del autoestopista galáctico, de Douglas Adams
