A diferencia de GPT-3, la inteligencia artificial de Diffbot genera gráficos de conocimiento de forma automática a partir de toda la información disponible en la web, en cualquier idioma. Ya se usa para buscar productos falsificados y hacer análisis financieros, entre otras aplicaciones
En julio, el último modelo de lenguaje de OpenAI, GPT-3 , dejó impresionada a mucha gente por su capacidad de generar párrafos que parecían escritos por un ser humano. Los usuarios empezaron a mostrar cómo GPT-3 también podía autocompletar el código y llenar espacios en blanco en hojas de cálculo.
Como ejemplo, el empleado de Twitter Paul Katsen tuiteó "la función de hoja de cálculo para dominarlas a todas", en la que GPT-3 llena las columnas por sí mismo, con datos sobre los estados de EE. UU.: la población de Michigan (EE. UU.) tiene 10,3 millones de habitantes, Alaska (EE. UU.) se convirtió en un estado en 1906, y así sucesivamente. Pero GPT-3 puede ser un poco mentiroso. La población de Michigan nunca ha tenido 10,3 millones de habitantes, y Alaska se convirtió en estado en 1959.
Los modelos de lenguaje como GPT-3 son imitadores asombrosos de las capacidades humanas, pero en realidad no entienden lo que están diciendo. "Son muy buenos para escribir historias sobre unicornios, pero no están entrenados para ser fácticos", opina el CEO de la start-up de Stanford (EE. UU.) Diffbot, Mike Tung.
Se trata de un problema si queremos que los sistemas de inteligencia artificial (IA) sean fiables. Es por eso que Diffbot adopta un enfoque diferente. Está construyendo una IA que lee todas las páginas públicas de internet, en varios idiomas, y extrae el máximo posible de los datos comprobados de esas páginas.
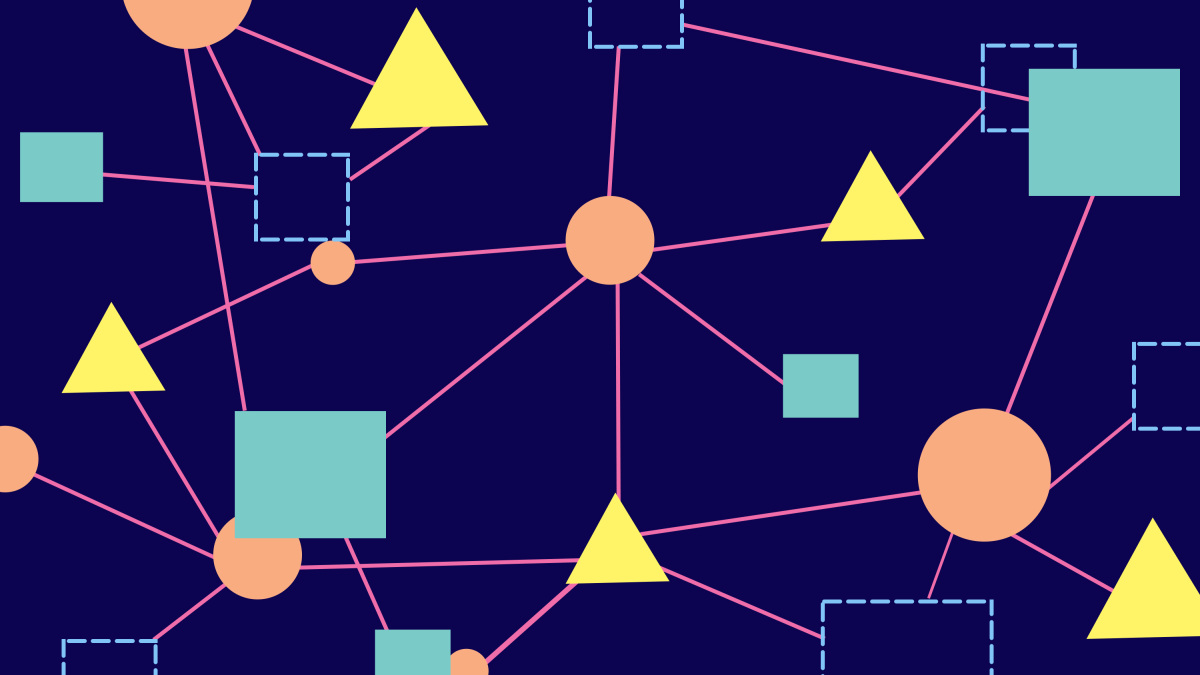
Al igual que GPT-3, el sistema de Diffbot aprende absorbiendo grandes cantidades de texto escrito por seres humanos que hay en la red. Pero en vez de usar los datos para entrenar un modelo de lenguaje, Diffbot convierte lo que lee en una serie de datos de tres partes que relacionan una cosa con otra: sujeto, verbo, objeto.
Al enseñarle mi biografía, por ejemplo, Diffbot aprendió que Will Douglas Heaven es periodista; Will Douglas Heaven trabaja en MIT Technology Review; MIT Technology Review es una empresa de medios de comunicación; etcétera. Cada uno de estos datos se une a miles de millones de otros en una extensa e interconectada red de datos. Esto se conoce como gráfico de conocimiento.
Los gráficos de conocimiento no son nuevos. Existen desde hace décadas y fueron un concepto fundamental en las primeras investigaciones de IA. Pero la creación y el mantenimiento de los gráficos de conocimiento normalmente se hace a mano, lo cual es difícil. Esto también impidió que Tim Berners-Lee se diera cuenta de lo que denominó la web semántica, que habría incluido información para máquinas y humanos, para que los bots pudieran reservar nuestros vuelos, realizar nuestras compras y dar respuestas más inteligentes a las preguntas de los motores de búsqueda.
Hace unos años, Google también comenzó a utilizar gráficos de conocimiento. Si buscamos "Katy Perry", aparecerá un cuadro junto a los resultados de la búsqueda principal que indica que Katy Perry es una cantautora estadounidense con su música disponible en YouTube, Spotify y Deezer. Se puede ver directamente que está casada con Orlando Bloom, tiene 35 años y 125 millones de dólares (105 millones de euros), y así sucesivamente. En lugar de ofrecernos una lista de enlaces a páginas sobre Katy Perry, Google nos brinda un conjunto de datos sobre ella extraídos de su gráfico de conocimiento.
Pero Google solo lo hace para sus términos de búsqueda más populares. Diffbot quiere hacerlo para todo. Al automatizar completamente el proceso de construcción, Diffbot ha sido capaz de crear el que podría ser el gráfico de conocimiento más grande de la historia.
Junto a Google y Microsoft, es una de las tres únicas empresas estadounidenses que rastrea toda la web pública. "Definitivamente tiene sentido rastrear la web. De lo contrario, hay que invertir mucho esfuerzo humano en crear una gran base de conocimientos", afirma la científica investigadora de Salesforce Victoria Lin que trabaja en el procesamiento del lenguaje natural (PLN) y la representación del conocimiento. El profesor de la Universidad de Mannheim (Alemania) Heiko Paulheim está de acuerdo: "La automatización es la única forma de crear gráficos de conocimiento a gran escala".
Súper navegador
Para recopilar sus datos, la IA de Diffbot lee la web como lo haría una persona humana, pero mucho más rápido. Mediante una versión más avanzada del navegador Chrome, la IA visualiza los píxeles de una página web y usa algoritmos de reconocimiento de imágenes para categorizar la página como uno de los 20 tipos diferentes, incluyendo vídeo, imagen, artículo, evento e hilo de discusión. Luego identifica los elementos clave de la página, como el título, el autor, la descripción del producto o el precio, y utiliza el PNL para extraer los datos de cualquier texto.
Cada dato de tres partes se añade al gráfico de conocimiento. Diffbot extrae los datos de páginas escritas en cualquier idioma, lo que significa que es capaz de responder a las preguntas sobre Katy Perry, por ejemplo, utilizando los datos extraídos de algunos artículos en chino o árabe, incluso si no contienen el término "Katy Perry".
Navegar por la web como un ser humano permite que la IA vea la misma información que nosotros. También significa que ha tenido que aprender a navegar por la web como nosotros. La IA debe desplazarse hacia abajo, cambiar de pestaña y cerrar los pop-ups. "La IA tiene que jugar en la web como si fuera un videojuego solo para experimentar las páginas", explica Tung.
Diffbot rastrea la web sin parar y reconstruye su gráfico de conocimiento cada cuatro o cinco días. Según Tung, la IA añade de 100 millones a 150 millones de entradas cada mes a medida que aparecen nuevas personas online, se crean empresas y se lanzan productos. Utiliza más algoritmos de aprendizaje automático para unir los nuevos hechos con los viejos, creando nuevas conexiones o reescribiendo las desactualizadas. Diffbot tiene que añadir nuevo hardware a su centro de datos a medida que crece el gráfico de conocimiento.
Los investigadores pueden acceder al gráfico de conocimiento de Diffbot de forma gratuita. Pero la compañía también tiene alrededor de 400 clientes de pago. El motor de búsqueda DuckDuckGo lo usa para generar sus propios cuadros similares a los de Google. Snapchat, para extraer lo más destacado de las páginas de noticias. La popular app de planificación de bodas Zola lo utiliza para ayudar a las personas a hacer sus listas de bodas, con imágenes y precios. Y NASDAQ, que ofrece información sobre el mercado de valores, se sirve de él para investigación financiera.
Buscar productos falsificados
Adidas y Nike lo utilizan incluso para buscar falsificaciones de sus productos en la web. Un motor de búsqueda ofrecerá una larga lista de sitios que mencionan las zapatillas Nike. Pero Diffbot permite que estas empresas busquen páginas web que realmente vendan sus deportivas, en lugar de simplemente hablar de ellas.
Por ahora, estas compañías deben interactuar con Diffbot mediante código. Pero Tung planea agregar una interfaz de lenguaje natural. En última instancia, quiere construir lo que denomina un "sistema universal de respuesta a preguntas fácticas": una IA que pueda responder a casi cualquier cosa que se le pregunte, con fuentes que respalden su respuesta.
Tung y Lin coinciden en que este tipo de IA no se puede construir únicamente con modelos de lenguaje. Funcionaría mejor aún si combinara distintas tecnologías, utilizando un modelo de lenguaje como GPT-3 para crear una interfaz similar a los seres humanos para un bot sabelotodo.
No obstante, incluso una IA que tiene los hechos claros no tiene por qué ser necesariamente inteligente. Tung concluye: "No estamos tratando de definir qué es la inteligencia, ni nada de eso. Solo estamos intentando construir algo útil".
Inteligencia Artificial
La inteligencia artificial y los robots están transformando nuestra forma de trabajar y nuestro estilo de vida.
-
OpenAI ha multiplicado casi por siete su inversión de 'lobby' ante la llegada de Trump
La empresa de Sam Altman aumenta su gasto en lobistas para influir en la política y definir el rumbo de la regulación de la IA

-
Minería paralela de datos, la técnica del nuevo traductor de Meta para dominar más de 100 idiomas
La aplicación presentada por Meta nos acerca a la creación de un dispositivo de traducción universal similar al Pez de Babel de La guía del autoestopista galáctico, de Douglas Adams

-
Convirtiendo los trinos en datos: esta IA estudia la migración de las aves a través del sonido
Tras décadas de frustración, las herramientas de aprendizaje automático están revelando a los ecologistas un tesoro de datos acústicos
