
La mayoría de la inteligencia artificial actual está guiada por el aprendizaje profundo, pero no siempre fue así. Un análisis de 16.625 artículos de IA de los últimos 25 años refleja cómo el aprendizaje reforzado y las redes neuronales y otros enfoques han ganado y perdido popularidad con el tiempo
Casi todo lo que escuchamos actualmente sobre inteligencia artificial (IA) se debe al aprendizaje profundo. Esta categoría de algoritmos utiliza estadísticas para encontrar patrones en los datos, y ha demostrado ser muy poderosa para imitar algunas habilidades humanas, como nuestra capacidad de ver y escuchar. Hasta cierto punto, incluso puede replicar nuestra capacidad de razonar. Estas funciones impulsan las búsquedas de Google, las noticias de Facebook y el motor de recomendaciones de Netflix, y están transformando industrias enteras como la salud y la educación.
Pero aunque el aprendizaje profundo ha introducido a la IA en la sociedad, solo representa un pequeño punto en toda la historia de la búsqueda de los humanos para replicar nuestra propia inteligencia. La técnica no lleva ni 10 años a la cabeza de este viaje. Así que cuando se abre el plano para ver todo el historial del campo, es fácil darse cuenta de que pronto podría estar en sus últimas.
El profesor de ciencias informáticas en la Universidad de Washington (EE.UU.) y autor de The Master Algorithm, Pedro Domingos, cuenta: "Si en 2011 alguien hubiera escrito que en unos años [el aprendizaje profundo] iba a ocupar las portadas de los periódicos y de las revistas, habríamos dicho: 'Wow, está alucinando'".
El experto explica que, durante años, los avances en inteligencia artificial estuvieron dominados por repentinos ascensos y caídas de diferentes técnicas. En cada década se ha vivido una competencia acalorada entre diferentes ideas. Después, de vez en cuando, algo cambia, y toda la comunidad se centra en una técnica específica.
En MIT Technology Review queríamos visualizar estos avances y retrocesos. Así que nos dirigimos a una de las bases de datos de código abierto más grandes de artículos científicos, arXiv. Descargamos los resúmenes de los 16.625 artículos de investigación disponibles en la sección de "inteligencia artificial" hasta el 18 de noviembre de 2018, y rastreamos las palabras mencionadas a través de los años para ver cómo ha evolucionado el campo.
Número de artículos descargados de arXiv
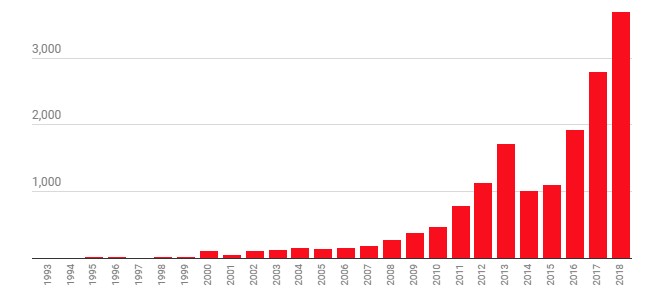
Gráfico: Todos los artículos disponibles en la sección de "inteligencia artificial" hasta el 18 de noviembre de 2018.
En nuestro análisis, encontramos tres tendencias principales: un giro hacia el aprendizaje automático a finales de la década de 1990 y principios de la década de 2000, un aumento en la popularidad de las redes neuronales a partir de principios de la década de 2010 y un reciente despunte del aprendizaje reforzado.
Hay que aclarar un par de cosas. Primero, la sección de IA del arXiv solo se remonta hasta 1993, mientras que el término "inteligencia artificial" apareció la década de 1950. Por lo tanto, la base de datos solo refleja los últimos capítulos de la historia del campo. En segundo lugar, los artículos añadidos cada año a la base de datos son solo una parte del trabajo del campo. No obstante, arXiv es un gran recurso para conocer algunas de las mayores tendencias de investigación y para ver el ir y venir de las diferentes ideas.
El marco del aprendizaje automático
El cambio más grande que encontramos fue un alejamiento de los sistemas basados en el conocimiento que tuvo lugar a principios de la década de 2000. Estos programas informáticos se basan en la idea de que es posible usar reglas para codificar todo el conocimiento humano. Los investigadores dejaron de lado este enfoque y se pasaron al aprendizaje automático, la categoría de algoritmos a la que pertenece el aprendizaje profundo.
Entre las 100 palabras más mencionadas, aquellas relacionadas con los sistemas basados en el conocimiento, como "lógica", "restricción" y "regla", son las que más dejaron de usarse. Las palabras relacionadas con el aprendizaje automático, como "datos", "red" y "rendimiento", fueron las que más aumentaron.
El aprendizaje automático eclipsa al razonamiento basado en el conocimiento
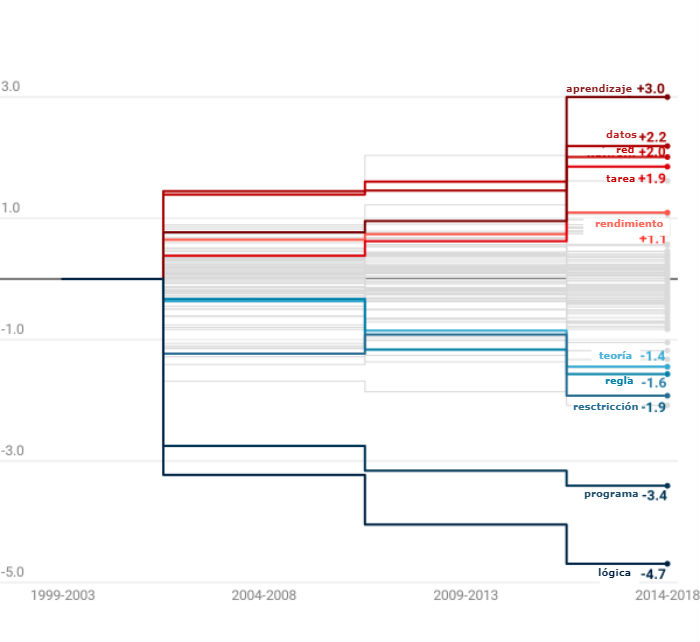
Gráfico: Variación de las 1.000 palabras mencionadas frente a las 100 palabras más usadas.
Frecuencia de términos por cada 1.000 palabras
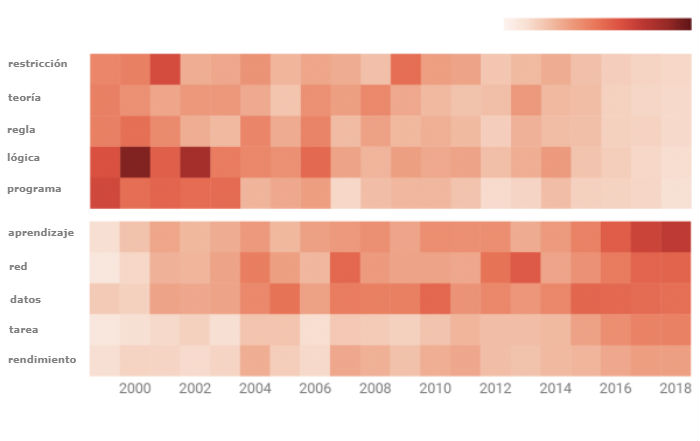
La razón de este cambio es bastante simple. En la década de 1980, los sistemas basados en el conocimiento ganaron muchos seguidores gracias a la ilusión que generaron algunos ambiciosos proyectos que intentaban recrear el sentido común dentro de las máquinas. Pero a medida que avanzaban, los investigadores se toparon con un problema importante: había que codificar demasiadas reglas para que un sistema hiciera algo útil. Esto aumentó los costes y redujo mucho las iniciativas en curso.
El aprendizaje automático se convirtió en la respuesta a ese problema. En vez de necesitar que las personas codifiquen manualmente cientos de miles de reglas, la técnica programa a las máquinas para que extraigan esas reglas automáticamente a partir de un grupo de datos. De esa manera, el campo abandonó los sistemas basados en el conocimiento y se dedicó a refinar el aprendizaje automático.
El bum de las redes neuronales
Bajo el nuevo paradigma del aprendizaje automático, el paso hacia el aprendizaje profundo tardó en suceder. Como muestra nuestro análisis de términos clave, los investigadores probaron una variedad de métodos además de las redes neuronales, la maquinaria central del aprendizaje profundo. Otras técnicas populares eran las redes bayesianas, las máquinas de soporte vectorial y los algoritmos evolutivos, todos con diferentes planteamientos para encontrar patrones en los datos.
Las redes neuronales toman el relevo
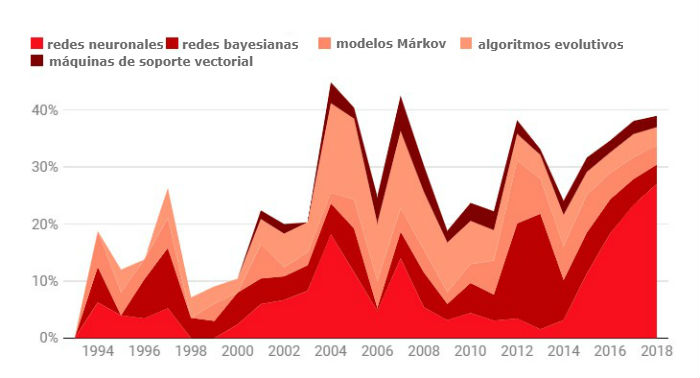
Gráfico: % de artículos que mencionan cada método
A lo largo de las décadas de 1990 y 2000, hubo una competencia constante entre todos estos métodos. Luego, en 2012, un avance fundamental dio paso a otro cambio radical. Durante la competición anual de ImageNet, con la intención de estimular los avances de visión artificial, el investigador de la Universidad de Toronto (Canadá) Geoffrey Hinton (actualmente conocido como el padre del aprendizaje profundo) y sus colegas lograron la mejor precisión en el reconocimiento de imágenes con un margen sorprendente de más de 10 puntos porcentuales.
La técnica que utilizó, el aprendizaje profundo, dio lugar una ola de nuevas investigaciones, que aunque primero se centró en la visión artificial, más tarde empezó a abarcar muchas más áreas. A medida que aumentaba el número de investigadores que comenzaron a usarlo para lograr resultados impresionantes, su popularidad se expandió, junto con la de las redes neuronales.
El auge del aprendizaje reforzado
En los pocos años posteriores el nacimiento del aprendizaje profundo, según nuestro análisis, se produjo un tercer y último gran cambio en la investigación de la IA.
Dentro de las diferentes técnicas de aprendizaje automático, existen tres tipos diferentes: el aprendizaje supervisado, el aprendizaje no supervisado y el aprendizaje reforzado. El aprendizaje supervisado, que consiste en alimentar a una máquina con datos etiquetados, es el más utilizado y también tiene las aplicaciones más prácticas. Pero en los últimos años, el aprendizaje reforzado, que imita el proceso de entrenamiento de animales a través de castigos y recompensas, ha vivido un rápido aumento de menciones.
El aprendizaje reforzado está ganando el terreno
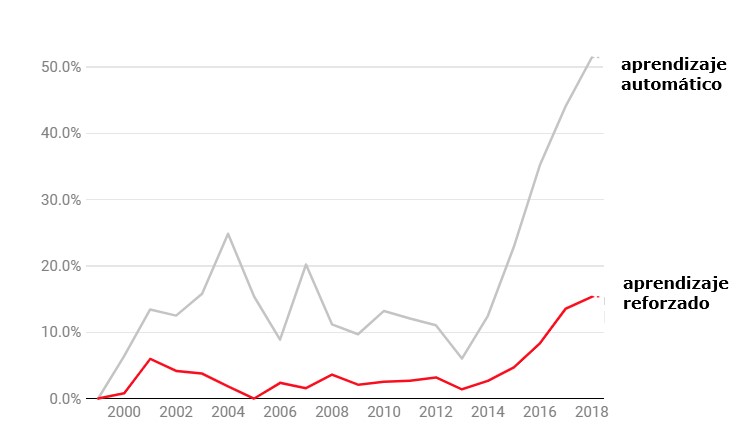
Gráfico:Artículos que lo mencionan frente a cualquier tipo de aprendizaje automático.
Aunque el enfoque no es nuevo, tardó décadas en funcionar. "La gente del aprendizaje supervisado se burlaba de la gente del aprendizaje reforzado", recuerda Domingos. Pero, al igual que pasó con el aprendizaje profundo, de repente, un momento crucial lo colocó en el mapa.
Ese momento llegó en octubre de 2015, cuando el algoritmo AlphaGo de DeepMind, entrenado con el aprendizaje reforzado, derrotó al campeón mundial en el antiguo juego de Go. El efecto en la comunidad investigadora fue inmediato.
La próxima década
Nuestro análisis ofrece solo un resumen de la competencia más reciente entre los distintos enfoques de IA. Pero también ilustra la inestabilidad en los intentos de reproducir la inteligencia humana. "La clave está en que nadie sabe cómo resolver el problema", opina Domingos.
Muchas de las técnicas utilizadas en los últimos 25 años nacieron casi a la vez, en la década de 1950, y a lo largo de los años han vivido diferentes desafíos y éxitos. Las redes neuronales, por ejemplo, alcanzaron su punto máximo en la década de 1960 y brevemente en la de 1980, pero casi se estaban muriendo antes de recuperar su popularidad actual a través del aprendizaje profundo.
En otras palabras, cada década ha estado dominada por una técnica diferente: de las redes neuronales a finales de las décadas de 1950 y 1960, a los métodos simbólicos de la década de 1970, luego los sistemas basados en el conocimiento en la década de 1970, d las redes bayesianas en la década de 1990, las máquinas de soporte vectorial en los años 2000 y las redes neuronales de nuevo en la década de 2010.
Domingos cree que la década de 2020 no debería ser diferente, lo que significa que la era del aprendizaje profundo pronto llegará a su fin. Pero, como de costumbre, la comunidad de investigación tiene distintas ideas enfrentadas sobre lo que vendrá después: si una técnica más antigua recuperará la aceptación general o si el campo creará un paradigma completamente nuevo. Domingos concluye: "Si respondemos a esa pregunta, quiero patentar la respuesta".
Inteligencia Artificial
La inteligencia artificial y los robots están transformando nuestra forma de trabajar y nuestro estilo de vida.
-
El modelo o3-mini de OpenAI, una IA más eficiente y con capacidad de "razonar"
OpenAI ha lanzado o3-mini, un modelo de razonamiento más económico y preciso que su predecesor, diseñado para mejorar la generación de respuestas complejas

-
DeepSeek cuestiona la idea de que la IA necesita más energía
El desarrollo de DeepSeek desafía la creencia de que solo un aumento en la potencia de cálculo puede impulsar avances en inteligencia artificial

-
El hambre de energía de la IA alimenta el resurgir nuclear
Cambios globales, avances tecnológicos y demanda de centros de datos: esto es lo que está por venir en 2025 y más allá
