
El aprendizaje profundo logra que las máquinas superen la prueba de razonamiento verbal, la única en la que todavía eran inferiores
Hace poco más de 100 años el psicólogo alemán William Stern introdujo la prueba de cociente intelectual (IQ) como método de evaluación de la inteligencia humana. Desde entonces, las pruebas IQ se han convertido en un estándar en la vida moderna y se utilizan para determinar la aptitud escolar de los niños y la capacidad de adultos de rendir en un trabajo.
Estas pruebas generalmente contienen tres categorías de preguntas: preguntas de lógica, como patrones en secuencias de imágenes; preguntas matemáticas, como encontrar el patrón dentro de secuencias de números, y preguntas de razonamiento verbal, que se basan en analogías, clasificaciones, y sinónimos y antónimos.
Es esta última categoría la que ha llamado la atención de Huazheng Wang y sus compañeros de la Universidad de Ciencias y Tecnologías de China, y de Bin Gao y su equipo de Investigaciones de Microsoft en Pekín. A los ordenadores nunca se les han dado bien. Plantea una pregunta de razonamiento verbal a una máquina de procesamiento de lenguaje natural y su rendimiento será pobre, mucho peor que la habilidad media humana.
Hoy esto cambia, gracias a Huazheng y su equipo, que han construido una máquina de aprendizaje profundo que supera la capacidad media humana de contestar preguntas de razonamiento verbal por primera vez.
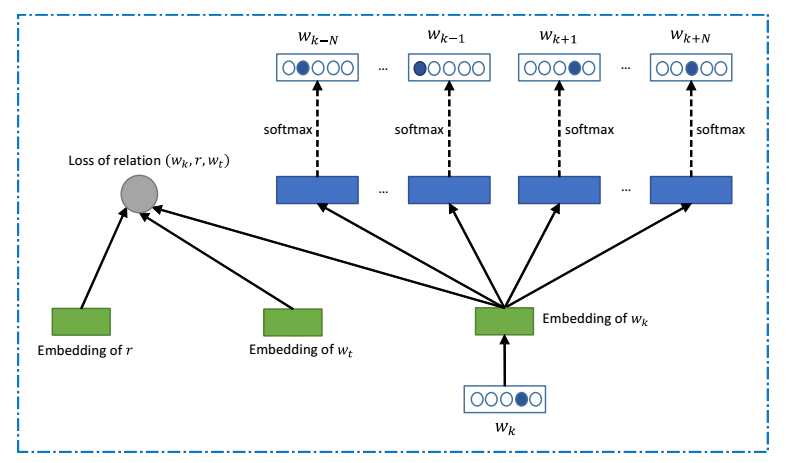
En años recientes, los informáticos han utilizado técnicas de minado de datos para analizar enormes cuerpos de texto para encontrar la conexión entre las palabras que contienen. Esto les permite controlar las estadísticas de los patrones de palabras en particular, como la frecuencia con la que aparece una palabra concreta cerca de otras palabras. Desde allí es posible averiguar cómo se relacionan las palabras entre sí, aunque dentro de un espacio de parámetros enormes.
El resultado final es que las palabras se pueden considerar como vectores en este espacio de parámetros de grandes dimensiones. La ventaja es que entonces pueden ser tratados matemáticamente: comparadas, añadidas y restadas como otros vectores. Esto lleva a otras relaciones entre vectores como esta: rey - hombre + mujer = reina.
Este enfoque ha obtenido un éxito enorme. Google lo emplea en la traducción automática con la suposición de que las secuencias de palabras en distintos idiomas representados por vectores similares tienen un significado equivalente. Así que representan la traducción el uno del otro.
Pero este enfoque tiene una desventaja bien conocida: supone que cada palabra tiene un sólo significado representado por cada vector. No sólo se demuestra con cierta frecuencia que este no es el caso, las pruebas verbales tienen a centrarse en palabras con más de un significado como técnica para aumentar la dificultad de las preguntas.
Huazheng y sus compañeros se enfrentan a esto cogiendo cada palabra por separado, y buscando otras palabras que aparecen a menudo junto a ella dentro un gran corpus de texto. Entonces emplean un algoritmo para ver cómo se agrupan las palabras. El paso final es buscar los distintos significados en un diccionario y entonces emparejar las agrupaciones con el significado adecuado.
Esto se puede hacer de forma automática porque la definición del diccionario incluye frases de ejemplo que muestran los distintos usos de la palabra. Así, calculando la representación vectorial de estas frases y comparándolas con la representación vectorial de las agrupaciones de palabras, es posible emparejarlas.
El resultado general representa un método de reconocer los significados múltiples que pueden tener algunas palabras.
Huazheng y su equipo tienen otro as en la manga para facilitar que los ordenadores puedan contestar preguntas de razonamiento verbal. Esto surge del hecho de que las preguntas corresponden a varias categorías que requieren enfoques ligeramente distintos entre sí para su resolución.
Así que su idea es empezar por identificar la categoría a la que pertenece cada pregunta, para que el ordenador sepa cuál de las estrategias emplear. Esto resulta bastante sencillo puesto que las preguntas de cada categoría tienen estructuras similares.
De manera que las preguntas que contienen analogías se parecen a estas:
- Isotermo es para la temperatura como isobara es para: (i) la atmósfera (ii) el viento (iii) la presión (iv) la latitud (v) la corriente
- Identifique dos palabras (una de cada grupo) que forman una conexión (analogía) cuando se emparejen con las palabras escritas en mayúsculas: CAPITULO (libro, verso, leer), ACTUAR (escenario, público, obra).
Las preguntas de clasificación de palabras se parecen a esta:
- ¿Cuál de estas palabras no encaja? (i) tranquilo (ii) silencio (iii) relajado (iv) sereno (v) impeturbable
Y las preguntas que buscan sinónimos y antónimos tienen esta estructura:
- ¿Cuál de estas palabras se asemeja más a IRRACIONAL? (i) intransigente (ii) irredimible (iii) peligroso (iv) perdido (v) absurdo
- ¿Cuál de estas palabras es el opuesto de MUSICAL? (i) discordante (ii) ruidoso (iii) lírico (iv) verbal (v) eufónico
Identificar el tipo de pregunta resulta bastante fácil para un algoritmo de aprendizaje artificial, dadas suficientes ejemplos de los que aprender. Y así es exactamente como lo consigue el equipo de Huazheng.
Habiendo identificado el tipo de pregunta, Huazheng y sus colegas entonces definen un algoritmo para la resolución de cada tipo mediante el uso de los métodos estándar de vectores pero también la mejora multisentido que han desarrollado.
Comparan esta técnica de aprendizaje profundo con otros enfoques algorítmicos para las pruebas de razonamiento verbal y también con la capacidad humana de realizarlas. Para ello, plantearon las preguntas a 200 humanos reunidos en las instalaciones Mechanical Turk de crowdsourcing de Amazon junto con otra información acerca de sus edades y estudios.
Y los resultados son impresionantes. "Para nuestra sorpresa, el rendimiento medio humano es un poco más bajo que el de nuestro propuesto de método", dicen.
El rendimiento humano en estas pruebas tiende a guardar una correlación con el nivel de estudios previos del individuo. Así las personas que recibieron una educación secundaria tienden a sacar los resultados más humildes, mientras que puntúan mejor los licenciados, y los que poseen un máster sacan los mejores resultados. "Nuestro modelo puede alcanzar un nivel de inteligencia que figura entre medias de los licenciados y los que cursaron un doctorado", dice el equipo de Huazheng.
Es un trabajo fascinante que revela el potencial de las técnicas de aprendizaje profundo. El equipo de Huazheng es claramente optimista sobre futuros avances. "Con el uso apropiado de las tecnologías de aprendizaje profundo, podemos estar un paso más cerca de la verdadera inteligencia humana".
Las técnicas de aprendizaje profundo corren por el mundo de la informática como un reguero de pólvora, y la revolución que impulsan está aún en fase temprana. No se sabe a dónde no llevará esta revolución, pero hay una cosa segura: William Stern estaría asombrado.
Ref: arxiv.org/abs/1505.07909: Solving Verbal Comprehension Questions in IQ Test by Knowledge-Powered Word Embedding
Computación
Las máquinas cada vez más potentes están acelerando los avances científicos, los negocios y la vida.
-
Google anuncia un hito hacia la computación cuántica sin errores
Una técnica llamada “código de superficie” permite a los bits cuánticos de la empresa almacenar y manipular datos fielmente durante más tiempo, lo que podría allanar el camino a ordenadores cuánticos útiles

-
El vídeo es el rey: bienvenido a la era del contenido audiovisual
Cada vez aprendemos y nos comunicamos más a través de la imagen en movimiento. Esto cambiará nuestra cultura de manera inimaginable

-
Esta empresa quiere superar a Google e IBM en la carrera cuántica con un superordenador de fotones
La empresa quiere construir una computadora que contenga hasta un millón de cúbits en un campus de Chicago
