
Posee la capacidad de leer la descripción de una escena, como una foto de un paraguas, y luego evocar una imagen de ello
Imagina un roble en mitad de un campo de trigo, una silueta sobre el cielo azul y despejado de una tarde de verano. La mayoría de los que lean esta frase podrán evocar la imagen de esta escena tan bucólica con la mente. Esta capacidad de leer la descripción de una escena e imaginarlo a continuación siempre ha sido una cualidad estrictamente humana. Pero puede que esta valiosa habilidad ya no sea sólo nuestra.
Cualquiera que piense que este tipo de imaginaciones están fuera del alcance de los ordenadores de hoy se sorprenderá con el trabajo de Hiroharu Kato y Tatsuya Harada de la Universidad de Tokio (Japón).
El equipo presenta una máquina que puede traducir una descripción de un objeto a una imagen visual; es decir, su ordenador puede generar la imagen de un objeto externo que no está presente. Es una definición bastante buena de lo que es la imaginación, en este caso de la variedad artificial.
Desde luego son representaciones imaginarias muy sencillas, a veces confusas e incluso carentes de sentido. Pero el hecho de que sean posibles representa un paso significativo hacia la creatividad computacional.
Hace mucho tiempo que los informáticos teóricos luchan para manejar las imágenes con la facilidad con la que los ordenadores dominan la palabra escrita. Es bastante sencillo, por ejemplo, introducir una palabra o frase en un buscador y recibir coincidencias altamente relevantes.
Esto no se debe a alguna capacidad computacional misteriosa para comprender el significado de las palabras. Se consigue simplemente tratando las palabras de forma estadística, como contar palabras mientras se sacan de una bolsa. De hecho este tipo de técnicas de "bolsas de palabras" se ha vuelto muy poderosa. En cambio no existe la capacidad equivalente para las imágenes.
Así que hace un par de años los informáticos teóricos empezaron a tratar las imágenes de la misma manera. Empezaron por pensar en una imagen como una serie de píxeles que dividen en secuencias cortas que corresponden a una parte concreta de la imagen. Por ejemplo una secuencia corta puede corresponder al borde de una taza, o a un trozo de piel, o a parte del cielo, y así.
Estas secuencias cortas bien poco significan para los humanos, pero un ordenador puede tratarlas igual que hace con las palabras. Así un ordenador podría analizar una imagen contando el número de secuencias y la frecuencia con la que aparecen, igual que haría con un documento al contar el número de palabras. Una imagen del cielo tendría muchas secuencias que corresponden a partes del cielo. Y una imagen de una taza de té tendría muchas secuencias que corresponden al borde de una taza, y así sucesivamente.
Esto permite la comparación inmediata de imágenes. Un ordenador puede consultar una base de datos de imágenes previamente analizadas con este método en busca de patrones de secuencias similares en otras imágenes. La idea es que dos imágenes con distribuciones de secuencias similares deberían tener aspectos parecidos, y los investigadores han tenido éxito aplicando esta técnica para encontrar correspondencias.
Por su analogía con el texto, los informáticos llaman a estas secuencias "palabras visuales", y este nuevo enfoque se conoce como la técnica bag-of-words. Analiza una imagen contando la distribución estadística de las palabras visuales que contiene.
La cuestión que abordan Kato y Harada es lo contrario de esto. Dada una distribución de palabras visuales, ¿cuál era la imagen original? Es un problema más complejo de resolver porque aunque una palabra visual describe parte de una imagen, no explica en qué parte de la imagen se ubicaba ni con qué otras palabras visuales lindaba.
"Este problema es similar a la resolución de un puzle", dicen los investigadores. Las palabras visuales son las piezas del puzle, y el problema a resolver es decidir cómo juntarlas todas para formar una imagen completa y coherente.
Kato y Harada decidieron encarar el problema de dos maneras distintas. La primera fue evaluar cómo palabras visuales individuales encajan de forma continua con las demás palabras visuales. Por ejemplo, todas las palabras visuales que describen el borde de una taza se pueden juntar para formar la imagen de un borde continuo.
Esto no es sencillo puesto que las palabras visuales no tienen una forma física y no se encajan de la misma manera que un puzle en el sentido literal. En vez de eso, Kato y Harada miden la relación entre palabras visuales dentro de una gran base de datos de imágenes contando el número de parejas de palabras visuales que aparecen juntas. Esto calcula la probabilidad de que estas palabras visuales deban colocarse de forma colindante.
El segundo método es establecer la probabilidad de que una palabra visual en concreto deba aparecer en lugar concreto de la imagen. Por ejemplo una palabra visual que muestra un trozo del cielo tiene más probabilidades de aparecer en la parte superior de la imagen.
Puesto que las palabras visuales en sí no contienen esta información, Kato y Harada lo miden utilizando de nuevo su gran base de datos de imágenes. "Se asume que cada palabra visual tendrá una preferencia en cuanto a su colocación absoluta", dicen. Esta preferencia es el valor medido de la base de datos.
Por supuesto que estos cálculos son computacionalmente complejos, en función del tamaño tanto de la base de datos como de las palabras visuales.
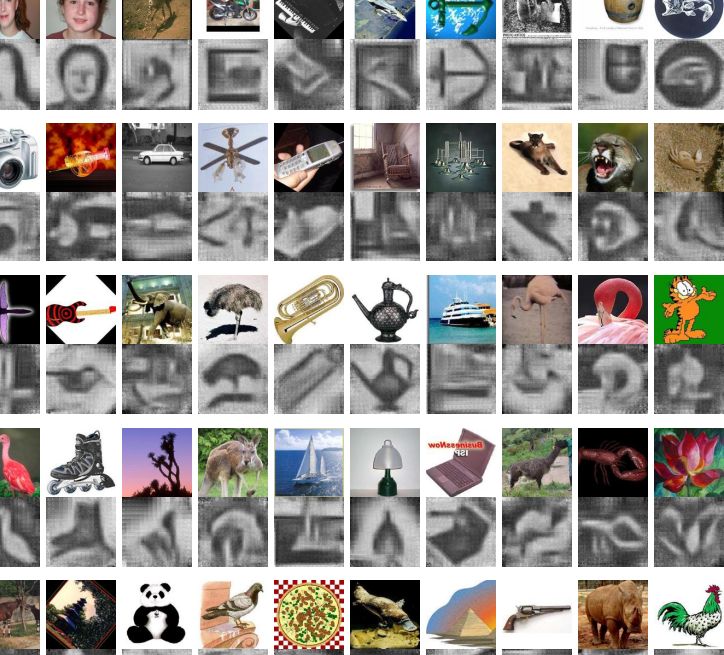
No obstante, Kato y Harada han conseguido un logro considerable con su enfoque. Crean una base de datos de 101 imágenes, cada una de un objeto distinto. Cambian el tamaño de cada imagen a 128 x 128 píxeles y suponen que cada imagen es compuesta por palabras visuales de 13 x 13 píxeles cada una, y que tres cuartas partes de cada palabra visual se solapa con la siguiente.
Habiendo creado ya la base de datos que muestra la distribución estadística de las palabras visuales, utilizan esta información para intentar volver a construir la imagen completa, únicamente a través de las palabras visuales que la componen.
Los resultados son, por lo general, impresionantes. Aunque algunas de las imágenes generadas no tienen sentido, otras recrean con éxito una amplia gama de imágenes como, por ejemplo, la de un paraguas, una llave inglesa, un barril, un pez, y hasta una cara humana (ver las imágenes recompuestas por ellos arriba).
El resultado impresiona y nos lleva a una variedad de otras aplicaciones útiles. Kato y Harada lo utilizan para la transformación de una imagen en otra, por ejemplo. Cogen "la bolsa de palabras visuales" que representa a dos imágenes, y generan bolsas de palabras visuales intermedias para crear las imágenes intermedias de la secuencia de transformación.
Más interesante aún es su trabajo sobre la visión artificial. Los informáticos teóricos han desarrollado recientemente potentes algoritmos para el reconocimiento automático que identifican objetos específicos. Estos algoritmos se conocen como clasificadores. Funcionan con un algo grado de precisión, pero a veces son engañados por objetos que parecen, al ojo humano, fáciles de identificar. Así que exactamente el qué buscan no está siempre muy claro.
El trabajo de Kato y Harada cambia esto. Han utilizado su versión del método "bolsa de palabras" para visualizar los clasificadores de objetos. "Esto revela diferencias entre la visión humana y la artificial", dicen.
Lo consiguen mediante el uso de clasificadores para el estudio de 10.000 imágenes escogidas al azar para contar las palabras visuales que disparan cada clasificador con más frecuencia. Entonces crean una imagen con estas palabras visuales mediante su técnica de bag-of-words.
Y los resultados son fascinantes. Algunos de los clasificadores visualizados son extraordinariamente similares a los objetos que representan, al menos hasta donde alcanza el reconocimiento humano. Otros son extrañamente deformados, como obras de arte moderno. Y otros muestran la importancia que pueden tener elementos adicionales, por ejemplo como el horizonte es importante para la identificación de árboles.
Por último, Kato y Harada utilizan su método para generar imágenes de frases corrientes. Hacen esto mediante la conversión de cada palabra de la frase en una bolsa de palabras visuales que luego convierten a una imagen.
Convertir palabras tradicionales en una bolsa de palabras es una tarea peliaguda. Los investigadores lo hacen buscando en un conjunto de datos de imágenes con etiquetas en forma de pie de foto. Cada vez que aparece una palabra en una etiqueta, añaden la palabra visual a una bolsa. Esto crea una gran bolsa de palabras visuales de la cual se puede generar una imagen.
Los resultados son fascinantes. "Algunas frases se traducen en imágenes sin ningún sentido", reconocen Kato y Harada. Esto probablemente se deba a que el método de convertir una palabra en una bolsa de palabras visuales sea demasiado sencillo. Pero otras frases generan imágenes, con cierta calidad de haberse salido de un sueño, que se asocian en líneas generales con la idea original (ver imágenes a continuación).

Kato y Harada aseguran que esto supone un comienzo prometedor y abre la puerta a nuevas generaciones de sistemas de creación de imágenes.
Es un trabajo realmente fascinante que supone un paso importante hacia la creatividad artificial. Pregúntale a Google por la definición de "imaginación" y te dirá esto: "La facultad o acción de formar ideas nuevas, o imágenes o conceptos de objetos externos que no están presente a efecto de los sentidos". Así que no supone ninguna exageración decir que Kato y Harada han creado la primera imaginación artificial del mundo.
Ref: arxiv.org/abs/1505.05190: Image Reconstruction from Bag-of-Visual-Words
Computación
Las máquinas cada vez más potentes están acelerando los avances científicos, los negocios y la vida.
-
Google anuncia un hito hacia la computación cuántica sin errores
Una técnica llamada “código de superficie” permite a los bits cuánticos de la empresa almacenar y manipular datos fielmente durante más tiempo, lo que podría allanar el camino a ordenadores cuánticos útiles

-
El vídeo es el rey: bienvenido a la era del contenido audiovisual
Cada vez aprendemos y nos comunicamos más a través de la imagen en movimiento. Esto cambiará nuestra cultura de manera inimaginable

-
Esta empresa quiere superar a Google e IBM en la carrera cuántica con un superordenador de fotones
La empresa quiere construir una computadora que contenga hasta un millón de cúbits en un campus de Chicago
