
Inteligencia Artificial
La IA generativa no necesita ser inteligente para amenazar el trabajo creativo
Nadie sabía lo popular que sería DALL-E de OpenAI en 2022, y nadie sabe a dónde nos llevará su desarrollo
Estaba claro que OpenAI había descubierto algo importante. A finales de 2021, un pequeño equipo de investigadores daba vueltas a una idea en su oficina de San Francisco (EE UU). Habían construido una nueva versión del modelo de conversión de texto en imagen de OpenAI, DALL-E, una inteligencia artificial (IA) que convierte breves descripciones escritas en imágenes: un zorro pintado por Van Gogh, tal vez, o un perro corgi hecho de pizza. Solo tenían que decidir qué hacer con eso.
"Casi siempre, construimos algo y luego tenemos que usarlo por un tiempo. Intentamos decidir qué va a ser, para qué se va a utilizar”, explica Sam Altman, cofundador y CEO de OpenAI, a MIT Technology Review.
Esta vez no fue así. Mientras jugueteaban con el modelo, los trabajadores se dieron cuenta de que era algo especial. "Estaba claro que esto era grande, era el gran producto. No hubo ningún debate. Ni siquiera tuvimos una reunión al respecto", recuerda Altman.
Nadie, ni Altman, ni el equipo de DALL-E, podía haber previsto el gran revuelo que iba a causar este producto. "Esta es la primera tecnología de IA que ha interesado tanto al gran público", asegura Altman.
DALL-E 2 se lanzó en abril de 2022. En mayo, Google anunció (aunque no lanzó) dos modelos propios que convierten texto en imagen: Imagen y Parti. Luego apareció Midjourney, el modelo de conversión de texto creado para artistas. Y en agosto de 2022, la start-up Stability AI (con sede en Reino Unido) lanzó Stable Diffusion, el modelo de código abierto, se de forma gratuita.
Las puertas estaban abiertas de par en par. OpenAI registró un millón de usuarios en solo dos meses y medio. Más de un millón de personas comenzaron a usar Stable Diffusion a través de su servicio de pago Dream Studio en menos de un mes; muchos usaron Stable Diffusion a través de las apps de terceros, o instalaron la versión gratuita en sus ordenadores. Emad Mostaque, fundador de Stability AI, afirma que su objetivo es llegar a mil millones de usuarios.
Luego, en octubre de 2022, tuvimos la segunda ronda: una serie de modelos de conversión de texto en vídeo de Google, Meta y otras empresas. No solo generan imágenes fijas, también pueden crear videoclips cortos, animaciones e imágenes en 3D.
El ritmo de desarrollo ha sido impresionante. En solo unos meses, la tecnología inspiró cientos de titulares de periódicos y portadas de revistas, llenó las redes sociales con memes, creó gran expectación, pero también una fuerte reacción negativa.
"La sorpresa y la admiración con esta tecnología resultan asombrosas, y es divertido, es lo que debería ser la nueva tecnología. Pero ha avanzado tan rápido que las primeras impresiones cambian antes de acostumbrarse a esa idea. Va a pasar un tiempo hasta que lo digiramos como sociedad", opina Mike Cook, investigador de IA del King's College de Londres (Reino Unido), que estudia la creatividad computacional.
Los artistas se ven atrapados en medio de uno de los mayores avances en una generación. Algunos perderán su trabajo, otros encontrarán nuevas oportunidades. Unos se dirigen a los tribunales para librar batallas judiciales por lo que consideran apropiación indebida de imágenes para entrenar modelos que podrían reemplazarlos.
Los creadores fueron sorpredidos, señala Don Allen Stevenson III, artista digital de California (EE UU), que ha trabajado en varios estudios de efectos visuales como DreamWorks. "Para personas técnicamente capacitadas como yo, es muy aterrador. Piensas, 'Dios mío, ese es todo mi trabajo. Entré en una crisis existencial durante el primer mes de uso de DALL-E", admite Allen Stevenson III.

Foto: La imagen de arriba se basa en una variación de la indicación "un artista que crea arte con una herramienta de arte de IA en Alien (1979)". El artista Erik Carter pasó por una serie de iteraciones para producir la imagen final (en la parte superior). "Después de encontrar una imagen con la que estaba conforme, entré e hice ajustes para limpiar cualquier artefacto de IA y hacer que pareciera más 'real'. Soy un gran admirador de la ciencia ficción de esa época", explica Carter. Créditos: Erik Carter vía DALL-E 2.
Sin embargo, mientras algunos todavía se están recuperando del impacto; muchos, incluido Stevenson, están encontrando formas de trabajar con estas herramientas y anticipar lo que vendría después.
La fascinante verdad es que no sabemos qué es lo próximo. Mientras las industrias creativas -desde los medios de entretenimiento hasta la moda, la arquitectura, el marketing y otras-, sentirán el impacto primero, esta tecnología otorgará súper poderes creativos a todos. A largo plazo, podría usarse para generar diseños para casi cualquier cosa, desde nuevos tipos de medicamentos hasta ropa y edificios. La revolución generativa ya ha comenzado.
Una revolución mágica
Para Chad Nelson, creador digital que ha trabajado en videojuegos y programas de televisión, los modelos que convierten texto en imagen son un avance único en la vida. "Esta tecnología te lleva en segundos desde esa bombilla que se enciende en tu cabeza a un primer boceto. La velocidad a la que podemos crear y explorar es revolucionaria, más allá de lo que he experimentado en 30 años", resalta Nelson.
A las pocas semanas de su debut, el público estaba usando estas herramientas para crear prototipos y realizar ideas de toda índole, desde ilustraciones de revistas y diseños de marketing hasta entornos de videojuegos y conceptos de películas. Los usuariosgeneraban fan art, incluso cómics completos, y los compartían online con miles de personas. Altman incluso utilizó DALL-E para crear diseños de zapatillas que una persona le hizo después de tuitear esa imagen.
Amy Smith, científica informática de la Universidad Queen Mary (Londres) y tatuadora , utiliza DALL-E para diseñar tatuajes. "Puedo sentarme con el cliente y generar diseños juntos. Estamos en una revolución de la generación de medios", reconoce Smith.
Paul Trillo, el artista digital y de vídeo californiano, cree que esta tecnología hará que proponer ideas para efectos visuales sea más fácil y rápido. "Se cree que esto es la muerte de los artistas de efectos o la muerte de los diseñadores de moda. Pero no creo que sea la muerte de nada. Esto significa que no tenemos que trabajar por las noches ni los fines de semana", considera Trillo.
Las empresas de imágenes de archivo están tomando diferentes posiciones. Getty ha prohibido las imágenes generadas por IA. Shutterstock firmó un acuerdo con OpenAI para incorporar DALL-E en su web y afirma que iniciará un fondo para reembolsar a los artistas cuyo trabajo se haya utilizado para entrenar a los modelos.
Stevenson cuenta que ha probado DALL-E en cada fase del proceso de producción de una película para un estudio de animación, incluido el diseño de personajes y entornos. Con DALL-E, pudo hacer el trabajo de varios departamentos en unos minutos. Stevenson considera que "Es alentador para todas las personas que nunca han podido crear porque era demasiado costoso o técnico. Pero es aterrador si no estás abierto al cambio".
Nelson opina que estamos al inicio de una transformación y ve que esta tecnología, con el tiempo, será adoptada no solo por los grandes medios de comunicación sino también por las empresas de arquitectura y diseño. Sin embargo, aún no está todo listo, indica.
"Ahora es como si tuviéramos una pequeña caja mágica, un pequeño mago", señala Nelson. Es genial si solo se quiere generar imágenes, pero no tanto si se necesita un socio creativo. "Si quiero que cree historias y construya mundos, hace falta mucha más conciencia de lo que estoy creando", explica el creativo.
Ese es el problema: estos modelos todavía no tienen ni idea de lo que están haciendo.
Dentro de la caja negra
Para descubrir por qué, veamos cómo funcionan estos programas. Desde fuera, el software es una caja negra. Hay que escribir una breve descripción, una indicación, y luego esperar unos segundos. Se recibe un puñado de imágenes que corresponden a esa indicación, más o menos. Puede que se deba modificar el texto para guiar al modelo a producir algo más cercano a lo que se tenía en mente, o para perfeccionar un resultado. Esto se conoce como la ingeniería de indicaciones.
Las indicaciones para las imágenes más detalladas y estilizadas pueden llegar a cientos de palabras, y encontrar los conceptos adecuados se ha convertido en una habilidad valiosa. Así han surgido mercados online de compra-venta de indicaciones que producen resultados deseables.
Estas instrucciones pueden contener frases que instruyen al modeloa usar un estilo particular, por ejemplo: "tendencia en ArtStation" le indica a la IA que imite el estilo (en general, muy detallado) de las imágenes populares en ArtStation, una web donde miles de artistas muestran su trabajo; "Unreal Engine" evoca el estilo gráfico familiar de ciertos videojuegos etc. Los usuarios pueden incluso introducir los nombres de artistas específicos para que la IA produzca imitaciones de su trabajo, lo que ha provocado el descontento de algunos de ellos.
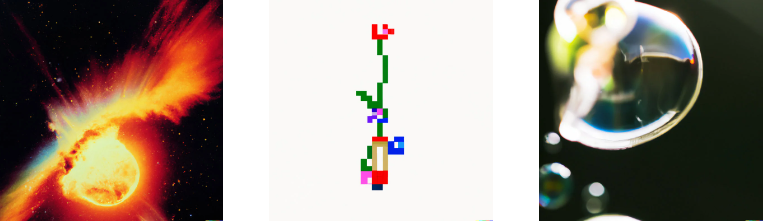
Fotos: "Traté de representar metafóricamente la IA con el texto 'Big Bang' y terminé con estas formas abstractas similares a burbujas (a la derecha). No era lo que quería, así que fui más literal con 'explosión en el espacio exterior en una fotografía de la década de 1980' (a la izquierda), que parecía demasiado agresiva. También intenté crear plantas digitales poniendo 'planta arte de píxeles de 8 bits' (en el centro)". Créditos: Erik Carter vía DALL-E 2.
Bajo el capó, los modelos que convierten texto en imagen tienen dos componentes clave: una red neuronal entrenada para emparejar una imagen con el texto que la describe y otra red entrenada para generar imágenes desde cero. La idea básica es que la segunda red neuronal genere una imagen que la primera red considere que coincide con el texto indicado.
El gran avance tras los nuevos modelos es la forma de generar las imágenes. La primera versión de DALL-E utilizó una extensión de tecnología del modelo de lenguaje GPT-3 de OpenAI, cuyas imágenes predicen el siguiente píxel en una imagen como si fueran palabras en una frase. Esto funcionó, aunque no muy bien. "No fue una experiencia mágica. Es increíble que, para empezar, haya funcionado ", confiesa Altman.
En cambio, DALL-E 2 utiliza un modelo de difusión. Este modelo se compone de redes neuronales entrenadas para limpiar las imágenes eliminando el ruido pixelado, añadido en el entrenamiento. En muchos pasos, ese proceso implica tomar imágenes y cambiar algunos píxeles hasta que las imágenes originales se borran y solo quedan píxeles aleatorios. "Si esto se hace mil veces, la imagen parecerá como si se hubiera arrancado el cable de la antena del televisor: solo habrá nieve", explica Björn Ommer, experto en IA generativa de la Universidad de Múnich (Alemania), que ayudó a construir el modelo de difusión de Stable Diffusion.
Luego, la red neuronal se entrena para revertir ese proceso y predecir cómo sería la versión menos pixelada de una imagen. El resultado es que, si se da un caos de píxeles, un modelo de difusión intentará generar algo más claro. Si vuelve a introducirse la imagen aclarada, el modelo producirá algo aún más nítido. Si esto se hace varias veces, el modelo puede transformar la nieve de la televisión en una imagen de alta resolución.
Los generadores de arte de IA nunca funcionan como queremos. A menudo, producen resultados espantosos que, en el mejor de los casos, pueden parecerse a obras de arte distorsionadas. Según mi experiencia, se hará un buen trabajo al agregar un descriptor al final con una estética atractiva - ErikCarter
El truco de los modelos que convierten texto en imagen es que este proceso está guiado por el modelo de lenguaje que busca las coincidencias entre texto e imágenes que produce el modelo de difusión. Esto empuja al modelo de difusión hacia imágenes que el modelo de lenguaje considera coincidentes.
Sin embargo, los modelos no extraen vínculos entre texto e imagen de la nada. La mayoría de los modelos actuales de conversión de texto a imagen están entrenados por LAION, un conjunto de datos con millones de pares de texto e imágenes extraídos de internet. Esto significa que las imágenes que se obtienen de un modelo de conversión de texto en imagen son síntesis del mundo tal y como se representa online, es decir, distorsionado por los prejuicios (y la pornografía).
Un último dato: existe una pequeña pero crucial diferencia entre los dos modelos más populares, DALL-E 2 y Stable Diffusion. El modelo de DALL-E 2 funciona con imágenes de tamaño completo. En cambio, Stable Diffusion utiliza una técnica de difusión latente, inventada por Ommer y sus colegas. Dicha técnica funciona con versiones comprimidas de imágenes codificadas dentro de la red neuronal en el espacio latente, donde solo se conservan las características esenciales de una imagen.
Así Stable Diffusion necesita menos potencia informática para funcionar. A diferencia de DALL-E 2, que se ejecuta en los potentes servidores de OpenAI, Stable Diffusion puede operar en (buenos) ordenadores personales. Gran parte de la explosión de creatividad y el rápido desarrollo de nuevas apps se debe al hecho de que Stable Diffusion es de código abierto -los programadores pueden cambiarlo, desarrollarlo y ganar dinero con él- y lo suficientemente fácil para que los usuarios lo utilicen.
Redefiniendo la creatividad
Para algunas personas, estos modelos son un paso más hacia la inteligencia artificial general, IAG (AGI, por sus siglas en inglés), una palabra de moda que se refiere a una futura IA con habilidades generales, incluso similares a las humanas. OpenAI ha sido explícito sobre su objetivo de lograr la AGI. Por esa razón, a Altman no le importa que DALL-E 2 compita con muchas herramientas similares, y algunas gratuitas. "Estamos aquí para hacer AGI, no generadores de imágenes. Eso encajará en una amplia hoja de ruta de productos. Es una pequeña muestra de lo que AGI hará", resalta Altman.
Eso es bastante optimista, como mínimo, ya que muchos expertos creen que la IA actual nunca alcanzará ese nivel. En cuanto a la inteligencia básica, los modelos de conversión de texto en imagen no son más inteligentes que las IA generadoras de lenguaje que los sustentan. Las herramientas como GPT-3 y PaLM de Google regurgitan patrones de texto ingeridos de los miles de millones de documentos con los que fueron entrenados. Del mismo modo, DALL-E y Stable Diffusion reproducen asociaciones entre textos e imágenes de millones de ejemplos online.
Si bienos resultados son deslumbrantes, al profundizar, la ilusión se hace añicos. Estos modelos cometen errores básicos, responden a "salmón en un río" con una imagen de filetes flotando río abajo; o a "un bate volando sobre un estadio de béisbol" con una imagen del mamífero volador (murciélago es bat en inglés) y un palo de madera. Esto se debe a que están construidos sobre una tecnología que no comprende el mundo como los humanos, o la mayoría de animales.
Aun así, puede ser solo cuestión de tiempo antes de que estos modelos aprendan mejores trucos. "La gente insiste en que no es muy bueno en esto ahora y, por supuesto, no lo es . Pero con 100 millones de dólares, podría serlo", resalta Cook.
Ese es claramente el enfoque de OpenAI.
"Ya sabemos cómo volverlo 10 veces mejor. Sabemos que hay tareas de razonamiento lógico que confunde. Vamos a revisar una lista de cosas y lanzaremos una nueva versión que solucione todos los problemas actuales", reconoce Altman.
Si las afirmaciones sobre la inteligencia y la comprensión son exageradas, ¿qué pasa con la creatividad? Entre los seres humanos, pensamos que los artistas, los matemáticos, los empresarios, los niños de guarderías y sus maestros son ejemplos de creatividad. Pero resulta difícil vislumbrar qué tienen en común estas personas.
Para algunos, lo más importante son los resultados. Otros argumentan que es primordial la forma de hacer las cosas, y si hay un objetivo en ese proceso.
Aun así, muchos recurren a una definición de Margaret Boden, influyente investigadora de IA y filósofa de la Universidad de Sussex (Reino Unido), quien reduce el concepto a tres criterios clave: para ser creativo, una idea o un artefacto debe ser nuevo, sorprendente y valioso.
Más allá de eso, a menudo se trata de reconocerlo al verlo. Los investigadores en el campo de la creatividad computacional describen su trabajo como el uso de ordenadores para generar resultados que se considerarían creativos, si se produjeran solo por personas.
Por lo tanto, Smith parece dispuesta a denominar como creativa a esta nueva generación de modelos generativos, a pesar de su estupidez. "Está claro que hay innovación en estas imágenes que no está controlada por ningún aporte humano. La traducción de texto a imagen suele ser sorprendente y bonita", explica la científica.
María Teresa Llano, especialista en creatividad computacional de la Universidad de Monash en Melbourne (Australia), concuerda en que los modelos de conversión de texto en imagen amplían las definiciones anteriores. Pero Llano no cree que sean creativos. Cuando estos programas se usan mucho, los resultados pueden empezar a volverse repetitivos, según Llano. Esto significa que no cumplen con algunos, o con ninguno, de los requisitos de Boden. Eso podría ser la limitación fundamental de la tecnología. Por diseño, un modelo de conversión de texto en imagen produce nuevas imágenes parecidas a millones de otras imágenes que ya existen. Quizás el aprendizaje automático solo produzca imágenes que imiten lo que ha estado expuesto en el pasado.
Eso podría no importar para los gráficos generados por ordenador. Adobe ya está incorporando la generación de texto a imagen en Photoshop; Blender, el primo de código abierto de Photoshop, tiene un plug-in de Stable Diffusion. OpenAI colabora con Microsoft en un widget de conversión de texto a imagen para Office.

Foto: DALL-E 2 acepta una imagen o texto escrito como indicación. La imagen de arriba se creó al subir la imagen final de Erik Carter de nuevo en DALL-E 2 como indicación. Créditos: Erik Carter vía DALL-E 2.
En este tipo de interacción, en las versiones futuras de estas herramientas, donde se vería el impacto real: las máquinas no reemplazan la creatividad humana sino que la mejoran. "La creatividad que ahora vemos proviene del uso de los sistemas, y no de los propios sistemas en sí", explica Llano sobre el intercambio de respuestas requerido para producir el resultado deseado.
Esta visión la comparten otros investigadores de creatividad computacional. No se trata solo de lo que hacen estas máquinas, sino de cómo lo hacen. Convertirlas en socios creativos significa empujarlas a tener más autonomía, darles responsabilidad creativa paracrear y también dirigir.
Algunos de estos aspectos llegarán pronto. Alguien ya ha escrito un programa denominado CLIP Interrogator, que analiza una imagen y crea una indicación para generar imágenes similares. Otros utilizan el aprendizaje automático para aumentar las indicaciones simples con frases diseñadas para dar calidad y fidelidad adicionales a una imagen, automatizando de manera efectiva la ingeniería de indicaciones, una tarea que existe desde hace pocos meses.
Mientras continúa la avalancha de imágenes, también estamos sentando otras bases. "Internet está contaminado para siempre con imágenes creadas por IA. Las imágenes que hemos generado en 2022 serán parte de cualquier modelo que se haga a partir de ahora", advierte Cook.
Tendremos que esperar para ver qué impacto duradero tendrán estas herramientas en las industrias creativas, y en todo el campo de la Inteligencia Artificial. La IA generativa se ha convertido en una herramienta más de expresión. Altman afirma que, en la actualidad, usa imágenes generadas en mensajes personales igual que antes usaba emojis. "Algunos amigos ni siquiera se molestan en generar la imagen, solo escriben la indicación", añade Altman.
Sin embargo, los modelos de conversión de texto en imagen pueden ser solo el inicio. La IA generativa podría usarse en el futuro para diseñar de todo, desde nuevos edificios hasta nuevos medicamentos, como la conversión de texto en contenido.
"La gente se dará cuenta de que la técnica o la destreza ya no es la barrera, ahora solo cuenta la capacidad de imaginar", opina Nelson.
Los ordenadores ya se utilizan en varias industrias para generar una gran cantidad de posibles diseños, que luego se seleccionan para encontrar aquellos que podrían funcionar. Los modelos de conversión de texto a contenido permitirían a un diseñador humano afinar ese proceso generativo desde el principio, empleando palabras para guiar a los ordenadores a través de un número infinito de opciones hacia resultados que no solo son posibles sino también deseables.
Los ordenadores pueden idear espacios de posibilidades infinitas. La conversión de texto a contenido nos permitirá explorar esos espacios utilizando las palabras.
Altman concluye: "Creo que ese es el legado. Imágenes, vídeo, audio, más adelante, todo eso se generará. Creo que se va a infiltrar en todas partes".
Inteligencia Artificial
La inteligencia artificial y los robots están transformando nuestra forma de trabajar y nuestro estilo de vida.
-
Minería paralela de datos, la técnica del nuevo traductor de Meta para dominar más de 100 idiomas
La aplicación presentada por Meta nos acerca a la creación de un dispositivo de traducción universal similar al Pez de Babel de La guía del autoestopista galáctico, de Douglas Adams

-
Convirtiendo los trinos en datos: esta IA estudia la migración de las aves a través del sonido
Tras décadas de frustración, las herramientas de aprendizaje automático están revelando a los ecologistas un tesoro de datos acústicos

-
Mundos virtuales generativos y modelos que "razonan": qué nos depara la IA en 2025
Ya sabemos que los agentes y los pequeños modelos lingüísticos serán las grandes tendencias del futuro. No obstante, destacamos otras cinco tendencias que deberías seguir de cerca este año
