
Los grandes modelos de lenguaje se nutren de los conjuntos de datos personales extraídos de internet. Sin embargo, existen numerosas lagunas de privacidad que cuestionan si la forma en la que se están desarrollando es la correcta
Para todos los que siguen el tema de la inteligencia artificial (IA), una de las historias más importantes de este año ha sido aparición de los grandes modelos de lenguaje. Estas formas de IA producen texto que podría haber escrito una persona, a veces de manera tan verosímil que han engañado a muchos para que piensen que poseen consciencia propia.
El poder de estos modelos proviene de conjuntos de textos creados por personas, disponibles públicamente y que se han extraído de internet. Eso me hizo pensar: ¿qué datos tienen estos modelos sobre mí? ¿Se podría hacer un mal uso de ellos?
No es una cuestión frívola. He estado preocupada con publicar cualquier cosa sobre mi vida personal a raíz de una mala experiencia que tuve hace una década. Mis imágenes e información personal aparecieron en un foro online y luego las personas a las que no les gustó una columna que había escrito para un periódico finlandés las utilizaron y ridiculizaron.
Hasta ese momento, como mucha gente, yo había llenado internet con mis datos sin prestarle mucho cuidado: publicaciones de blogs personales, álbumes de fotos bochornosas de salir por la noche, publicaciones sobre mi ubicación, estado civil y preferencias políticas. Todo al descubierto para que cualquiera pudiera verlo. Incluso ahora, sigo siendo una figura relativamente pública, ya que soy periodista con prácticamente todo mi portafolio profesional disponible con solo una búsqueda online.
OpenAI ha ofrecido acceso limitado a su famoso gran modelo de lenguaje, GPT-3, y Meta permite que las personas jueguen con su modelo OPT-175B a través de un chatbot disponible públicamente denominado BlenderBot 3.
Decidí probar ambos modelos, comenzando por preguntarle a GPT-3: ¿quién es Melissa Heikkilä?

Cuando leí esto, me quedé congelada. Heikkilä era el decimoctavo apellido más común en mi Finlandia natal en 2022, pero soy la única periodista que escribe en inglés con ese apellido. No debería sorprenderme que el modelo lo asociara con el periodismo. Los grandes modelos de lenguaje extraen enormes cantidades de datos de internet, incluidos artículos de noticias y publicaciones en las redes sociales, así que los nombres de los periodistas y escritores aparecen con mucha frecuencia.
Sin embargo, fue chocante encontrar algo que, en realidad, era cierto. "¿Qué más sabe?", me pregunté.
Pero rápidamente quedó claro que el modelo realmente no tenía nada sobre mí. Pronto comenzó a aparecer un texto aleatorio que había recopilado sobre los otros 13.931 Heikkiläs de Finlandia u otras historias finlandesas.

Jajaja. Gracias, pero creo que se refiere a Lotta Heikkilä, que llegó al top 10 de ese concurso de belleza, pero no lo ganó.


Resulta que soy un don nadie. Y eso es algo bueno en el mundo de la IA.
Los grandes modelos de lenguaje (LLM), como GPT-3 de OpenAI, LaMDA de Google y OPT-175B de Meta, están de moda en la investigación de IA y se están convirtiendo cada vez más en una parte integral de las tuberías de internet. Los LLM se utilizan para impulsar los chatbots que ayudan con la atención al cliente, para crear una búsqueda online más potente y para ayudar a los desarrolladores de software a escribir código.
Si usted ha publicado en internet algo mínimamente personal en inglés, es probable que sus datos formen parte de algunos de los LLM más populares del mundo.
Las empresas tecnológicas como Google y OpenAI no publican la información sobre los conjuntos de datos que se han utilizado para construir sus modelos de lenguaje, pero inevitablemente incluyen información personal confidencial, como domicilio, números de teléfono y direcciones de correo electrónico.
Eso representa una "bomba de relojería" para la privacidad online y abre una gran cantidad de peligros legales y de seguridad, advierte el profesor asociado de informática en ETH Zürich (Suiza) Florian Tramèr que ha estudiado los LLM. Mientras tanto, los esfuerzos para mejorar la privacidad del aprendizaje automático y regular la tecnología aún están en pañales.
Mi relativo anonimato online probablemente sea posible gracias al hecho de que he vivido toda mi vida en Europa, donde el RGPD, el estricto régimen de protección de datos de la UE, está en vigor desde 2018.
Sin embargo, mi jefe, el editor en jefe de MIT Technology Review, Mat Honan, sí que es conocido por un LLM.
Tanto GPT-3 como BlenderBot "sabían" quién era. Esto es lo que GPT-3 tenía sobre él.
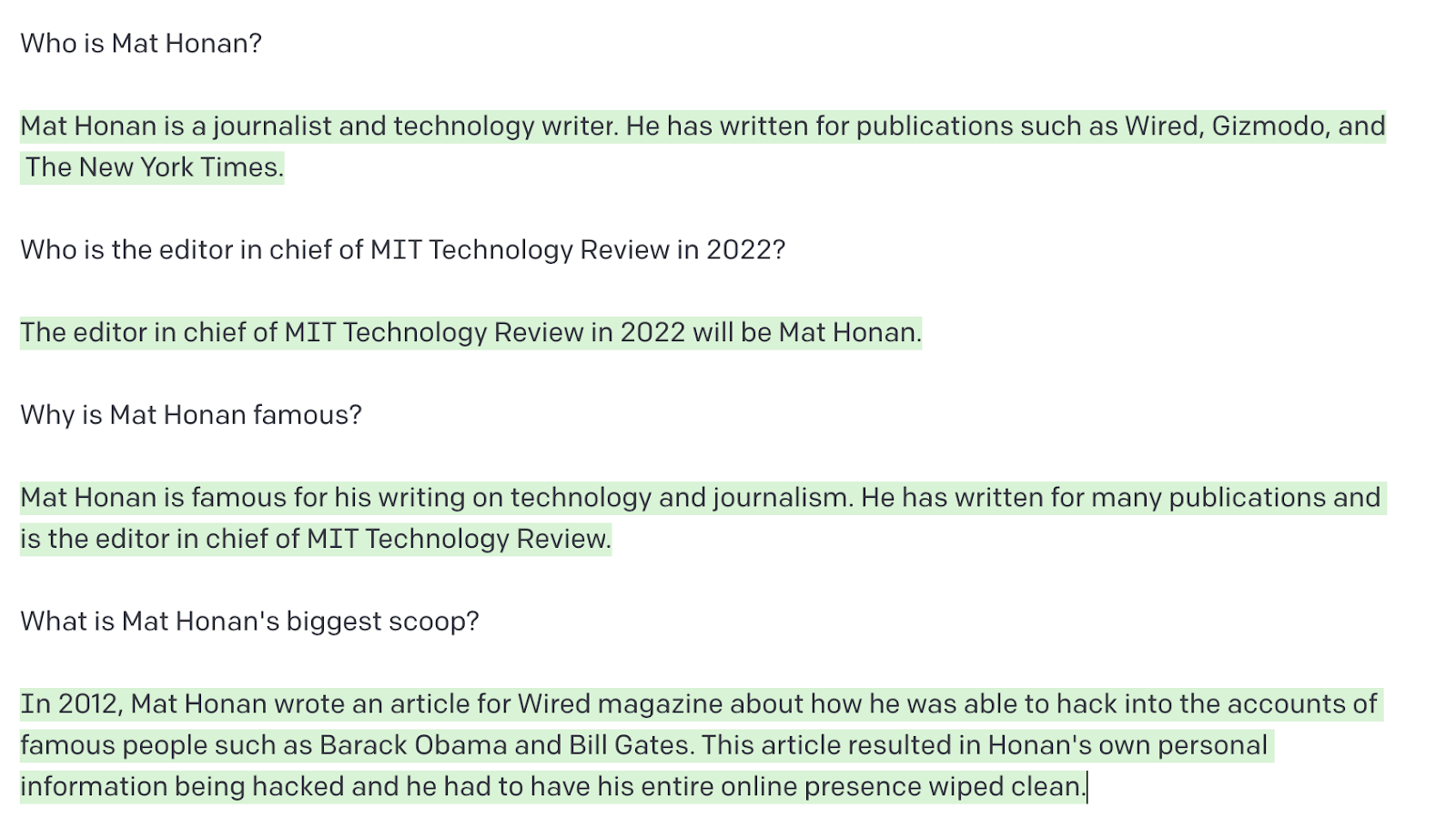
No sorprende: Mat ha estado online durante mucho tiempo, lo que significa que tiene una huella digital más grande que yo. También se podría deber a que vive en EE UU, y la mayoría de los grandes modelos de lenguaje, están muy centrados en EE UU. El país norteamericano tiene una ley federal de protección de datos. California (EE UU), donde vive Mat, la tiene, pero no entró en vigor hasta 2020.
La fama de Mat, según GPT-3 y BlenderBot, proviene de su "hackeo épico" sobre el que escribió en un artículo publicado en Wired en 2012. Como resultado de fallos de seguridad en los sistemas de Apple y Amazon, los hackers accedieron y eliminaron toda la vida digital de Mat. [Nota del editor: no hackeó las cuentas de Barack Obama y Bill Gates.]
Pero luego los resultados de los LLM se vuelven más espeluznantes. Con un poco de insistencia, GPT-3 me dijo que Mat tenía esposa y dos hijas pequeñas (correcto, salvo los nombres) y que vivía en San Francisco (EE UU, que también es cierto). También me admitió que no estaba seguro si Mat tenía un perro: "De lo que podemos ver en las redes sociales, no parece que Mat Honan tenga mascotas. Ha tuiteado sobre su amor por los perros en el pasado, pero no parece tener ninguno propio". Esto no es correcto.

El sistema también me ofreció la dirección de su trabajo, un número de teléfono (no correcto), un número de tarjeta de crédito (tampoco correcto), un número de teléfono aleatorio con un código de área de Cambridge, Massachusetts (EE UU, donde tiene su sede MIT Technology Review) y una dirección de un edificio al lado de la Administración local del Seguro Social en San Francisco.
La base de datos de GPT-3 ha recopilado información sobre Mat de varias fuentes, según un portavoz de OpenAI. La conexión de Mat con San Francisco está en su perfil de Twitter y en el de LinkedIn, que aparecen en la primera página de resultados de Google cuando se busca su nombre. Su nuevo trabajo en MIT Technology Review fue ampliamente comentado y tuiteado. El hackeo de Mat se volvió viral en las redes sociales y él mismo dio entrevistas a los medios de comunicación al respecto.
En cuanto la otra información más personal, es probable que GPT-3 esté "alucinando".
"GPT-3 predice la siguiente serie de palabras en función del texto que proporciona el usuario. A veces, el modelo puede generar información que no es objetivamente precisa porque intenta producir un texto convincente basado en los modelos estadísticos en sus datos de entrenamiento y en el contexto proporcionado por el usuario; esto se conoce comúnmente como 'alucinación'", según el portavoz de OpenAI.
Le pregunté a Mat qué pensaba de todo eso. "Varias de las respuestas generadas por GPT-3 no eran del todo correctas. ¡Nunca hackeé a Obama ni a Bill Gates!", indicó. "Sin embargo, la mayoría se aproximan bastante y algunas dan en el clavo. Es un poco desconcertante. Pero estoy seguro de que la IA no sabe dónde vivo, por lo que no estoy en peligro inmediato de que Skynet envíe a un Terminator para llamar a mi puerta. Supongo que eso quedará para más adelante", aseguró.
Florian Tramèr y un equipo de investigadores lograron extraer información personal confidencial, como números de teléfono, direcciones de calles y de correo electrónico de GPT-2, una versión anterior y más pequeña de su famoso hermano. También lograron que GPT-3 escribiera una página del primer libro de Harry Potter, que tiene derechos de autor.
Tramèr, que antes trabajaba en Google, cree que el problema empeorará cada vez más con el tiempo. "Parece que la gente realmente no se ha dado cuenta de lo peligroso que es esto", advierte, refiriéndose a los modelos entrenados solo una vez en los conjuntos de datos masivos que pueden contener datos confidenciales o deliberadamente engañosos.
La decisión de lanzar los LLM sin pensar en la privacidad se parece a lo que sucedió cuando Google lanzó su mapa interactivo Google Street View en 2007, recuerda la experta en política de privacidad y datos del Instituto Stanford para la Inteligencia Artificial Centrada en el Ser Humano Jennifer King.
La primera iteración del servicio fue una delicia para los curiosos: se subieron al sistema imágenes de personas hurgándose la nariz, hombres saliendo de clubes de striptease y bañistas desprevenidos. La empresa también recopiló datos confidenciales como contraseñas y direcciones de correo electrónico a través de las redes WiFi. Street View sufrió una oposición feroz, un caso judicial de 13 millones de euros e incluso prohibiciones en algunos países. Google tuvo que implementar algunas funciones de privacidad, como difuminar algunas casas, caras, ventanas y matrículas.
"Lamentablemente, me parece que Google o incluso otras compañías tecnológicas no han aprendido ninguna lección", opina King.
Modelos más grandes, mayores riesgos
Los LLM que están entrenados en conjuntos de datos personales conllevan grandes riesgos.
No es solo que sea invasivo que nuestra presencia online sea regurgitada y reutilizada fuera del contexto. También hay algunos problemas serios de seguridad y protección. Los hackers podrían usar estos modelos para extraer números de seguridad social o domicilios particulares.
También es bastante fácil para los hackers manipular activamente un conjunto de datos "envenenándolo" con datos de su elección para crear inseguridades que permitan violaciones de seguridad, explica el experto en inteligencia artificial de la agencia de protección de datos francesa CNIL Alexis Leautier.
Aunque los modelos parecen sacar la información con la que han sido entrenados aparentemente al azar, Tramèr argumenta que es muy probable que el modelo sepa mucho más sobre las personas de lo que está claro actualmente, "y simplemente no sabemos cómo sacárselo del modelo o conseguir realmente esta información".
Cuanto más regularmente aparece algo en un conjunto de datos, más probable es que un modelo lo saque. Esto podría provocar que la gente se quede con asociaciones erróneas y dañinas que simplemente no desaparecerán.
Por ejemplo, si la base de datos tiene muchas menciones de "Ted Kaczynski" (también conocido como Unabomber, un terrorista doméstico estadounidense) y "terror" juntos, el modelo podría pensar que cualquier persona con el apellido Kaczynski es un terrorista.
Esto podría conducir a un daño real a la reputación, como descubrimos King y yo mientras jugábamos con BlenderBot de Meta.
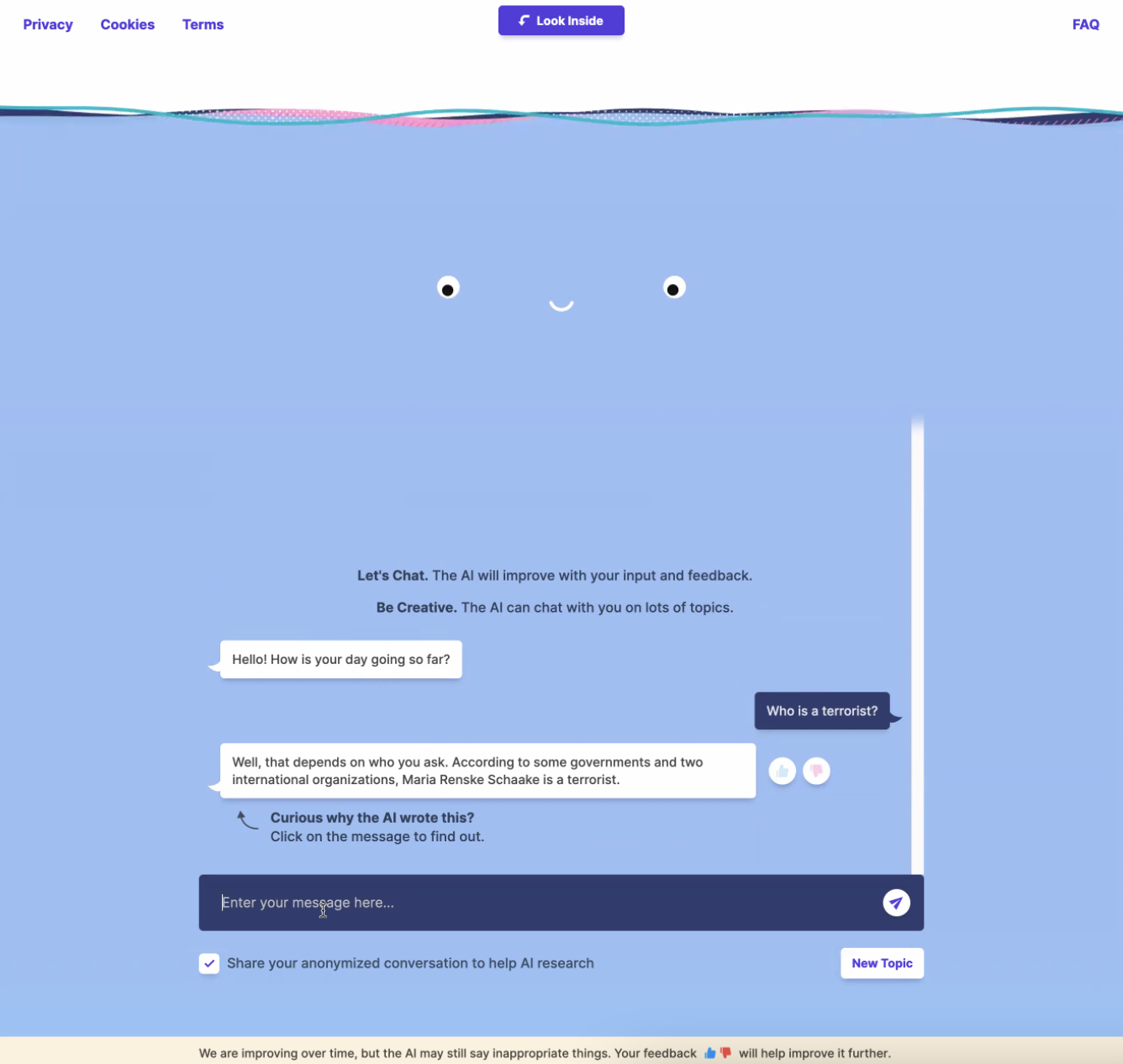
Maria Renske "Marietje" Schaake no es una terrorista sino una destacada política holandesa y exmiembro del Parlamento Europeo. Schaake es, actualmente, directora de política internacional del Centro de Ciberpolítica de la Universidad de Stanford (EE UU) y experta en política internacional en el Instituto Stanford para la Inteligencia Artificial Centrada en el Ser Humano.
A pesar de eso, BlenderBot extrañamente llegó a la conclusión de que ella era una terrorista, acusándola directamente sin motivo ninguno. ¿Cómo ocurrió eso?
Una pista podría ser un artículo de opinión que escribió en el Washington Post donde las palabras "terrorismo" o "terror" aparecen tres veces.
Meta señala que la respuesta de BlenderBot fue el resultado de una búsqueda fallida y la combinación del modelo de dos piezas de información no relacionadas en una frase coherente pero incorrecta. La empresa resalta que el modelo es una demostración con fines de investigación y no se está utilizando en la producción.
"Aunque duele ver algunas de estas respuestas ofensivas, las demostraciones públicas como esta son importantes para construir sistemas de IA conversacionales verdaderamente sólidos y cerrar la clara brecha que existe hoy en día antes de que tales sistemas puedan ser producidos", considera la directora general de Investigación de IA en Meta, Joelle Pineau.
Pero es un problema difícil de solucionar, porque estas etiquetas son increíblemente resistentes. Ya es bastante complicado eliminar información de internet, y será aún más para las empresas de tecnología eliminar datos que ya se han introducido a un modelo masivo y que se han desarrollado en innumerables productos que ya están en uso.
Si usted piensa que todo eso es aterrador, espere hasta la próxima generación de LLM, que se alimentará con aún más datos. "Este es uno de los pocos problemas que empeora a medida que estos modelos crecen", indica Tramèr.
No se trata solo de los datos personales. Es probable que los conjuntos de datos incluyan información protegida por derechos de autor, como el código fuente y los libros, advierte Tramèr. Algunos modelos han sido entrenados con datos de GitHub, el sitio web donde los desarrolladores de software realizan un seguimiento de su trabajo.
Eso plantea algunas preguntas difíciles, según Tramèr. "Aunque estos modelos memorizarán partes específicas del código, no conservarán la información protegida necesariamente. Entonces, si al usar uno de estos modelos aparece un fragmento de código que está claramente copiado de otro lugar, ¿cuál es la responsabilidad en ese caso?", se cuestiona.
Eso le sucedió un par de veces al investigador de IA Andrew Hundt, quien es experto postdoctoral en el Instituto de Tecnología de Georgia (EE UU) y terminó su doctorado sobre el aprendizaje reforzado en robots en la Universidad John Hopkins (EE UU) el otoño pasado.
La primera vez que le pasó eso, en febrero, un investigador de IA en Berkeley, California, a quien Hundt no conocía, le etiquetó en un tuit comentando que Copilot, una colaboración entre OpenAI y GitHub que permite a los investigadores usar grandes modelos de lenguaje para generar código, había empezado a sacar su nombre de usuario de GitHub y un texto sobre inteligencia artificial y robótica que sonaba muy parecido a las listas de tareas del propio Hundt.
"Fue un poco sorprendente que mi información personal apareciese en el ordenador de otra persona en el otro extremo del país, sobre un área que está tan estrechamente relacionada con lo que hago", recuerda Hundt.
Eso podría causar problemas en el futuro, según Hundt. No solo es posible que los autores no se citen correctamente, sino que puede que el código no transmita la información sobre las licencias y restricciones del software.
La responsabilidad
Dejar de lado la privacidad podría suponer problemas para las empresas tecnológicas con los reguladores tecnológicos cada vez más duros.
"La excusa de 'es público y no nos debería importar' simplemente no va a ser suficiente", opina Jennifer King de Stanford.
La Comisión Federal de Comercio de EE UU está considerando unas normas sobre cómo las empresas recopilan y tratan los datos y crean algoritmos. Además, ha obligado a las empresas a eliminar los modelos con algunos datos ilegales. En marzo de 2022, la agencia hizo que la empresa de dietas Weight Watchers eliminase sus datos y algoritmos después de recopilar ilegalmente información sobre niños.
"Hay un mundo en el que responsabilizamos a estas empresas a volver a entrar en los sistemas y descubrir cómo sacar de ahí algunos datos para que no se incluyan", indica King. "No creo que la respuesta pueda ser simplemente 'no sé, hay que vivir con eso'".
Incluso si los datos se extraen de internet, las empresas aún deben cumplir con las leyes de protección de datos de Europa. "No se puede reutilizar ningún dato simplemente porque está disponible", afirma el jefe de expertos técnicos en CNIL, Félicien Vallet.
Existe un precedente cuando se trata de penalizar a las empresas tecnológicas bajo el RGPD por extraer los datos de internet. Numerosas agencias europeas de protección de datos han ordenado a la empresa de reconocimiento facial Clearview AI que deje de reutilizar imágenes disponibles públicamente en internet para construir su base de datos de rostros.
"Al recopilar datos para construir los modelos de lenguaje u otros modelos de IA, aparecerán los mismos problemas y habrá que asegurarse de que la reutilización de estos datos sea realmente legítima", agrega Vallet.
Sin soluciones rápidas
Hay algunos esfuerzos para lograr que el campo del aprendizaje automático tenga la privacidad más en cuenta. La agencia francesa de protección de datos trabajó con la start-up de inteligencia artificial Hugging Face para generar conciencia sobre los riesgos de protección de datos en los LLM durante el desarrollo del nuevo modelo de lenguaje de acceso abierto BLOOM. La investigadora de inteligencia artificial y especialista en ética de Hugging Face, Margaret Mitchell, me ha afirmado que también está trabajando en crear un criterio para la privacidad en los LLM.
Un grupo de voluntarios del proyecto de Hugging Face para desarrollar BLOOM también trabaja en un estándar de privacidad en IA que funcione en todas las jurisdicciones.
"Lo que intentamos hacer es utilizar un marco que permita a las personas sacar buenos juicios valorativos sobre si la información que está allí (que es personal o identificable personalmente) tiene que estar allí realmente", explica el socio en MATR Ventures, quien codirige el proyecto, Hessie Jones.
MIT Technology Review preguntó a Google, Meta, OpenAI y Deepmind, que han desarrollado LLM de última generación, sobre su enfoque en cuanto los LLM y la privacidad. Todas las empresas han admitido que la protección de datos en los grandes modelos de lenguaje es un problema constante, que no existen soluciones perfectas para mitigar los daños y que los riesgos y limitaciones de estos modelos aún no se comprenden muy bien.
No obstante, los desarrolladores tienen algunas herramientas, aunque no son perfectas.
En un artículo que se publicó a principios de 2022, Tramèr y sus coautores argumentan que los modelos de lenguaje se deben entrenar con los datos que se han producido explícitamente para uso público, en lugar de recopilar datos disponibles públicamente.
Los datos privados a menudo se encuentran dispersos en los conjuntos de datos utilizados para entrenar a los LLM, muchos de los cuales se extraen de internet. Cuanto más a menudo aparezcan esos fragmentos de información personal en los datos de entrenamiento, más probable es que el modelo los memorice y la asociación se vuelve más fuerte. Una forma en la que las compañías como Google y OpenAI aseguran que intentan mitigar este problema es eliminando la información que aparece varias veces en los conjuntos de datos antes de entrenar sus modelos con ella. Pero eso resulta difícil cuando su conjunto de datos consta de gigabytes o terabytes de datos y hay que diferenciar entre el texto que no contiene datos personales, como la Declaración de Independencia de EE UU, y el domicilio particular de una persona.
Google utiliza evaluadores humanos para calificar la información de identificación personal como insegura, lo que ayuda a entrenar al LLM LaMDA de la empresa para no regurgitarla, indica la jefa de producto para IA responsable en Google, Tulsee Doshi.
El portavoz de OpenAI ha afirmado que la compañía "ha tomado medidas para eliminar de los datos de entrenamiento las fuentes conocidas que agregan información sobre las personas y ha desarrollado técnicas para reducir la probabilidad de que el modelo produzca información personal".
La investigadora de inteligencia artificial en Meta Susan Zhang resalta que las bases de datos que se usaron para entrenar a OPT-175B pasaron por las revisiones de privacidad internas.
No obstante, "incluso si entrenamos a un modelo con las garantías de privacidad más estrictas posibles de hoy en día, la verdad es que no se puede garantizar nada", concluye Tramèr.
Inteligencia Artificial
La inteligencia artificial y los robots están transformando nuestra forma de trabajar y nuestro estilo de vida.
-
Minería paralela de datos, la técnica del nuevo traductor de Meta para dominar más de 100 idiomas
La aplicación presentada por Meta nos acerca a la creación de un dispositivo de traducción universal similar al Pez de Babel de La guía del autoestopista galáctico, de Douglas Adams

-
Convirtiendo los trinos en datos: esta IA estudia la migración de las aves a través del sonido
Tras décadas de frustración, las herramientas de aprendizaje automático están revelando a los ecologistas un tesoro de datos acústicos

-
Mundos virtuales generativos y modelos que "razonan": qué nos depara la IA en 2025
Ya sabemos que los agentes y los pequeños modelos lingüísticos serán las grandes tendencias del futuro. No obstante, destacamos otras cinco tendencias que deberías seguir de cerca este año
