
Facebook afirma que su sistema supera con creces al líder previo, el chatbot Meena de Google, y las pruebas parecen confirmarlo. No obstante, aunque el sistema de conversación suena bastante natural en muchos temas, suele inventarse información y puede hacer comentarios tóxicos y sesgados
A pesar de todo el progreso que se ha logrado con los chatbots y los asistentes virtuales de conversación, la experiencia de hablar con ellos sigue siendo terrible. La mayoría están muy orientados a determinadas tareas específicas: hay que pedirles algo y ellos responden. Algunos son muy frustrantes: parece que nunca tienen lo que buscamos. Otros resultan muy aburridos: carecen del encanto de un compañero humano. Eso está bien cuando solo queremos poner el despertador. Pero a medida que estos bots se vuelven cada vez más populares como interfaces para todo, desde el comercio al por menor hasta la atención médica y los servicios financieros, los defectos solo parecen más evidentes.
Facebook acaba de publicar el código abierto de su nuevo chatbot, llamado Blender, del que afirma que es capaz de hablar sobre casi cualquier tema de forma amena e interesante. Blender no solo es capaz de ayudar a otros asistentes virtuales a resolver muchas de sus deficiencias, sino que también demuestra el progreso hacia la gran ambición que impulsa buena parte de la investigación de inteligencia artificial (IA): replicar la inteligencia. El ingeniero de investigación en Facebook y codirector del proyecto Stephen Roller afirma: "El diálogo es una especie de problema de 'IA completa'. Habría que resolver toda IA para resolver el diálogo, y si se resuelve el diálogo, se habrá resuelto toda IA".
La habilidad de Blender proviene de la inmensa cantidad de datos empleada en su de entrenamiento. Primero se entrenó con 1.500 millones de conversaciones de Reddit disponibles al público, lo que permitió darle una base para generar respuestas en un diálogo. Luego fue perfeccionado con conjuntos de datos adicionales para cada una de sus tres habilidades: conversaciones que contenían algún tipo de emoción, para enseñarle la empatía (si un usuario dice "Conseguí un ascenso", por ejemplo, puede responder con: "¡Felicidades!"); conversaciones con mucha información dirigidas a expertos, para enseñarle el conocimiento; y conversaciones entre personas con distintas personalidades, para enseñarle lo que es la personalidad. El modelo resultante es 3,6 veces mayor que el chatbot Meena de Google, que se presentó en enero, cuyo algoritmo es tan pesado que no cabe en un solo dispositivo y se debe ejecutar en dos chips informáticos.
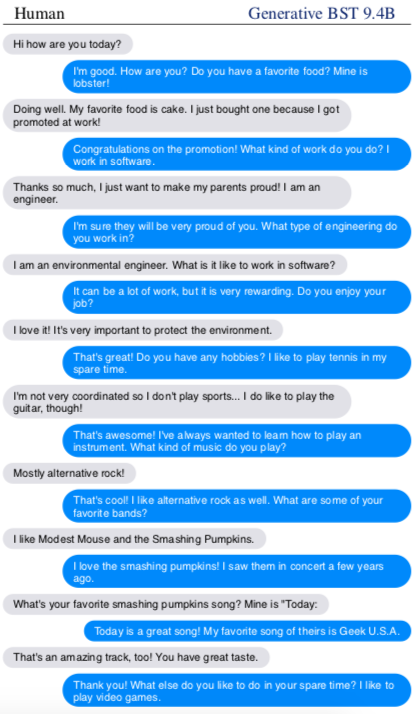
Traducción de la conversación entre un humano y Blender de Facebook
Hola. ¿Qué tal estás hoy?
Estoy bien. ¿Y tú? ¿Cuál es tu comida preferida? ¡La mía es la langosta!
Yo bien. Mi comida preferida es la tarta. ¡Acabo de comprar una porque me han ascendido en el trabajo!
¡Felicidades por el ascenso! ¿A qué te dedicas? Yo al software.
Muchas gracias. ¡Quiero que mis padres se sientan orgullosos de mí! Soy ingeniero.
Seguro que se sentirán orgullosos de ti. ¿Qué tipo de ingeniero eres?
Soy ingeniero medioambiental. ¿Cómo es trabajar con el software?
Puede haber mucho trabajo, pero es muy gratificante. ¿Disfrutas de tu trabajo?
¡Me encanta! Es muy importante proteger el medio ambiente.
¡Qué bien! ¿Tienes alguna afición? A mí me gusta jugar al tenis en mi tiempo libre.
No tengo muy buena coordinación así que no practico deporte… Pero me gusta tocar la guitarra.
¡Genial! Siempre he querido aprender a tocar algún instrumento. ¿Qué tipo de música tocas?
Rock alternativo, más que nada.
¡Qué bueno! A mí también me gusta el rock alternativo. ¿Cuáles son tus grupos preferidos?
Me gustan Modest Mouse y The Smashing Pumpkins.
¡Me encanta The Smashing Pumpkins! Fui a un concierto suyo hace un par de años.
¿Cuál es tu canción preferida de The Smashing Pumpkins? La mía es 'Today'.
¡'Today' es muy buena canción! La mía preferida es 'Geek U.S.A'.
¡Esa también es increíble! Tienes buen gusto.
¡Gracias! ¿Qué más te gusta hacer en tu tiempo libre? A mí me gustan los videojuegos.
En el momento de su presentación, Google proclamó que Meena era el mejor chatbot del mundo. Sin embargo, en las comprobaciones de Facebook, el 75 % de los evaluadores humanos encontraron que Blender era más participativo que Meena, y el 67 % consideraba que se parecía más a un humano. El chatbot también engañó a los evaluadores humanos el 49 % de las ocasiones, al hacerles creer que su conversación era más humana que la de personas reales, lo que significa que no había mucha diferencia cualitativa entre ellas. Google respondió a nuestra solicitud de comentarios antes de la publicación de este artículo.
Sin embargo, a pesar de estos impresionantes resultados, las habilidades de Blender todavía no se acercan a las de un ser humano. Hasta ahora, el equipo solo ha evaluado el chatbot en conversaciones cortas con 14 turnos. Los investigadores sospechan que, si mantiene una conversación más larga, esta no tardará en dejar de tener sentido. La otra corresponsable del proyecto, Emily Dinan, afirma: "Estos modelos no pueden ser muy profundos. No pueden recordar el historial de la conversación más allá de unas pocas frases".
Blender también tiene una tendencia a "alucinar" con lo que sabe, o a inventarse cosas, una limitación directa de las técnicas de aprendizaje profundo utilizadas para su creación. Al fin y al cabo, genera sus frases a partir de las correlaciones estadísticas en vez de a partir de una base de datos de conocimiento. Como resultado, puede ofrecer una descripción detallada y coherente de una celebridad, por ejemplo, cuya información completamente falsa. El equipo planea probar la integración de una base de datos de conocimiento en la generación de las respuestas del chatbot.
Otro desafío importante con cualquier sistema abierto de chatbot es evitar que haga comentarios abusivos o sesgados. Como esos sistemas se entrenan en redes sociales, pueden acabar sacando insultos de internet. (Es lo que lamentablemente ocurrió con el chatbot Tay de Microsoft en 2016). El equipo intentó abordar el problema pidiendo a los trabajadores que filtraran el lenguaje abusivo de los tres conjuntos de datos que utilizaron para la última fase, pero eso no se hizo con el conjunto de datos de Reddit debido a su tamaño. (Cualquiera que haya pasado mucho tiempo en Reddit entenderá por qué eso podría convertirse en un gran problema).
Sus creadores esperan lograr mejores mecanismos de seguridad, incluido un clasificador de lenguaje tóxico que haga doble verificación de la respuesta del chatbot. En cualquier caso, los investigadores admiten que este enfoque no tendrá un carácter integral. A veces, una frase como "Sí, eso es genial" podría parecer bien, pero dentro de un contexto sensible, como en respuesta a un comentario racista, puede tener significados dañinos.
A largo plazo, el equipo de IA de Facebook espera desarrollar agentes de conversación más sofisticados capaces de responder tanto a las señales visuales como a las palabras. En uno de sus proyectos están desarrollando un sistema llamado Image Chat que puede conversar con sensatez y personalidad sobre las fotos que envía un usuario.
Inteligencia Artificial
La inteligencia artificial y los robots están transformando nuestra forma de trabajar y nuestro estilo de vida.
-
Mundos virtuales generativos y modelos que "razonan": qué nos depara la IA en 2025
Ya sabemos que los agentes y los pequeños modelos lingüísticos serán las grandes tendencias del futuro. No obstante, destacamos otras cinco tendencias que deberías seguir de cerca este año

-
La IA acaba con la búsqueda en Google tal y como la conocemos
A pesar de la caída en el número de clics, las disputas sobre derechos de autor y las respuestas a veces poco fiables, la IA podría abrir nuevas maneras de acceder y aprovechar todo el conocimiento disponible en internet

-
Qué anticipan los errores de la IA en 2024 sobre su futuro
La IA ha traído grandes avances, pero también importantes fallos. En este repaso, destacamos los mayores fracasos del año, que van desde chatbots que ofrecen consejos ilegales hasta resultados de búsqueda poco fiables
