
La inteligencia artificial tiene un gran potencial para predecir brotes, realizar diagnósticos tempranos y encontrar candidatos a vacunas. Pero para ello, necesita una serie de datos que, o no se han generado todavía o no resultan accesibles, y puede que las formas de obtenerlos no le gusten demasiado
Parece ser que un sistema de inteligencia artificial (IA) vio venir al coronavirus (SARS-CoV-2). El 30 de diciembre, la compañía de inteligencia artificial BlueDot, que utiliza aprendizaje automático para detectar brotes de enfermedades infecciosas en todo el mundo, alertó a sus clientes, incluidos varios gobiernos, hospitales y empresas, sobre un inusual aumento de casos de neumonía en Wuhan (China). Nueve días más tarde, la Organización Mundial de la Salud lanzó el aviso oficial sobre lo que ahora todos conocemos como COVID-19.
BlueDot no fue la única empresa que lo detectó. El servicio automatizado HealthMap del Hospital Infantil de Boston (EE. UU.) también notó esas primeras señales. Lo mismo ocurrió con el sistema de la compañía Metabiota. Resulta impresionante que la IA sea capaz detectar un brote en el otro lado del mundo, y todos sabemos que las alertas tempranas salvan vidas.
Pero, ¿de verdad la IA ha contribuido algo para abordar esta pandemia? Es una pregunta difícil de responder. Las empresas como BlueDot no suelen revelar a quién proporcionan sus datos y ni cómo se utilizan. Y sus trabajadores humanos afirman que detectaron el brote el mismo día que la IA. Otros proyectos que están intentando usar la IA para desarrollar una herramienta de diagnóstico o para encontrar una vacuna todavía están en sus etapas iniciales. Incluso si lo consiguen, se tardará un tiempo, posiblemente meses, en convertir esas innovaciones en herramientas disponibles para el personal sanitario.
El bombo en torno a la inteligencia artificial contra el coronavirus está superando a la realidad. De hecho, lo que ha aparecido en muchos informativos y comunicados de prensa (que la IA es una nueva y poderosa arma contra enfermedades) solo es cierto en parte y podría resultar contraproducente. Por ejemplo, confiar excesivamente en las capacidades de IA podría provocar la toma de decisiones incorrectas por información equivocada que llevaría el dinero público a compañías de IA no comprobada a expensas de las intervenciones verificadas como los programas de medicamentos. También es malo para el propio campo: no sería la primera vez que las expectativas exageradas con resultados decepcionantes reducen el interés en la IA, lo que a su vez limita las inversiones.
La realidad es la siguiente: la IA no nos salvará del coronavirus, al menos en esta ocasión. Pero, si se llevan a cabo algunos cambios importantes, hay muchas probabilidades de que juegue un papel clave en futuras epidemias. La mayoría de esos cambios no serán fáciles. De hecho, algunos de ellos no nos gustarán.
Hay tres principales áreas en las que la IA podría ayudar: predicción, diagnóstico y tratamiento.
Predicción
Las empresas como BlueDot y Metabiota utilizan una variedad de algoritmos de procesamiento de lenguaje natural (PLN) para monitorizar medios de comunicación e informes oficiales de atención médica en diferentes idiomas en todo el mundo, y emiten una alerta si dichos contenidos mencionan enfermedades prioritarias, como el coronavirus, o endémicas, como el VIH y la tuberculosis. Sus herramientas de predicción también pueden utilizar datos de viajes aéreos para calcular el riesgo de los centros de tránsito por la llegada o salida de personas infectadas.
Los resultados son razonablemente acertados. Por ejemplo, el último informe público de Metabiota, del 25 de febrero, predijo que el 3 de marzo habría 127.000 casos en todo el mundo. Aunque se pasó unos 30.000, el director de Ciencia de Datos de la empresa, Mark Gallivan, asegura que la diferencia está dentro del margen de error. También enumeró los países con la mayor probabilidad de nuevos casos, incluidos China, Italia, Irán y EE. UU. De nuevo: no lo hizo nada mal.
Otros sistemas también están atentos a las redes sociales. La compañía de análisis de datos de Charlotte (EE. UU.) Stratifyd está desarrollando una IA que recoge las publicaciones de sitios como Facebook y Twitter y las combina con las descripciones de enfermedades tomadas de otras fuentes como los Institutos Nacionales de Salud de EE. UU., la Organización Mundial de Sanidad Animal (OIE) y la base de datos global de identificadores de microbios, donde se almacena la información de secuenciación de los genomas.
El trabajo de estas empresas es realmente impresionante y demuestra hasta qué punto ha avanzado el aprendizaje automático. Hace unos años, Google intentó predecir brotes con su desafortunado Flu Tracker (Rastreador de gripe), que se dejó de usar en 2013 cuando fue incapaz predecir el pico de gripe de aquel año. ¿Qué es lo que ha cambiado? Se trata principalmente de la capacidad del último software para buscar en una gama mucho más amplia de fuentes.
El aprendizaje automático no supervisado también es clave. Permitir que una IA identifique sus propios patrones entre el ruido, en vez de entrenarla en ejemplos preseleccionados, resalta algo que a lo mejor no se iba a buscar. "Cuando se quiere hacer predicciones, hay que buscar nuevos comportamientos", explica el CEO de Stratifyd, Derek Wang.
Pero, ¿para qué sirven exactamente esas predicciones? La primera predicción de BlueDot identificó correctamente un puñado de ciudades que se cruzarían en el camino del virus. Esto podría haber permitido a las autoridades a prepararse, alertar a los hospitales y establecer medidas de contención. Pero mientras crece la escala de la epidemia, las predicciones se vuelven menos específicas. La advertencia de Metabiota de que ciertos países se verían afectados en la semana siguiente podría haber sido correcta, pero resulta difícil saber qué hacer con esa información.
Además, todos estos enfoques serán menos precisos a medida que avance la epidemia, en gran parte porque los datos fiables sobre el COVID-19 que la IA necesita son difíciles de reunir. Distintas fuentes de noticias e informes oficiales ofrecen datos inconsistentes. La información sobre síntomas y sobre la forma en la que el virus se contagia entre las personas han ido cambiando. Los medios pueden amplificar la situación; las autoridades pueden minimizarla. Y tener la capacidad de predecir dónde se podría propagar el contagio desde cientos de sitios en docenas de países resulta mucho más complicado que emitir un aviso sobre dónde podría ocurrir un único brote en sus primeros días. "El ruido siempre es un obstáculo para los algoritmos de aprendizaje automático", afirma Wang. De hecho, Gallivan reconoce que las predicciones diarias de Metabiota fueron más fáciles en las primeras dos semanas.
Uno de los mayores obstáculos es la falta de pruebas de diagnóstico, destaca Gallivan. El responsable detalla: "Lo ideal sería que tuviéramos una prueba para detectar el nuevo coronavirus de inmediato y que pudiéramos revisar a todos al menos una vez al día". Tampoco sabemos realmente cómo se comportan las personas: quién trabaja desde casa, quién está en autocuarentena, quién se lava las manos o no, o qué efecto podría tener. Si queremos predecir lo que nos espera, necesitamos una imagen precisa de lo que ocurre en estos momentos.
Tampoco está claro qué es lo que pasa dentro de los hospitales. El experto de la consultora de datos e inteligencia artificial Pactera Edge, Ahmer Inam, asegura que las herramientas de predicción serían mucho mejores si los datos de salud pública no estuvieran ocultos en las agencias gubernamentales como ocurre en muchos países, incluido Estados Unidos. Esto significa que IA tiene que depender más de los datos fácilmente disponibles, como las noticias online. "Cuando los medios de comunicación se dan cuenta de una posible enfermedad nueva, ya es demasiado tarde", opina.
Pero si la IA necesita muchos más datos de fuentes fiables para ser útil, las estrategias para obtenerlos podrían parecer controvertidas. Varias personas con las que he hablado destacaron esta incómoda situación: para conseguir mejores predicciones del aprendizaje automático, debemos compartir más datos personales con empresas y gobiernos.
El MD y CEO de Apixio, Darren Schulte, cuya empresa ha creado una IA para extraer información del historial médico de los pacientes, cree que los registros médicos deberían abrirse para el análisis de datos. Esto podría permitir que la IA identifique automáticamente a las personas con mayor riesgo debido a enfermedades previas. En ese caso, los recursos se centrarían en aquellas personas que más los necesiten. La tecnología para buscar en los registros de pacientes y extraer información que salvaría vidas existe, según Schulte. El problema consiste en que estos registros se dividen en varias bases de datos y son gestionados servicios sanitarios diferentes, lo que los hace aún más difíciles de analizar. El responsable explica: "Me gustaría llevar mi IA a este gran océano de datos. Pero nuestros datos se encuentran en pequeños lagos, no en un gran océano".
Los datos médicos también se deberían compartir entre los países. Inam afirma: "Los virus no son activos solo dentro de los límites de las fronteras geopolíticas". Cree que debería existir un acuerdo internacional que obligue a los países a publicar los datos sobre diagnósticos e ingresos hospitalarios en tiempo real. Luego, esta información podría incorporarse a los modelos de aprendizaje automático de la pandemia a escala global.
Por supuesto, todo esto podría ser una mera ilusión. Las diferentes partes del mundo tienen distintas normativas de privacidad para los datos médicos. Y muchos de nosotros no queremos que nuestros datos se cedan a terceros. Las nuevas técnicas de procesamiento de datos, como la privacidad diferencial y el entrenamiento de sistemas con datos sintéticos en vez de reales, podrían ofrecer una solución a este debate. Pero esta tecnología aún se está perfeccionando. Lograr un acuerdo sobre las normas internacionales llevará aún más tiempo.
Por ahora, debemos aprovechar al máximo los datos que tenemos. La respuesta de Wang consiste en asegurarse de que las personas puedan interpretar los resultados que ofrezcan los modelos de aprendizaje automático, y descartar las predicciones que no parezcan posibles. Y subraya: "Ser demasiado optimistas o confiados en un modelo predictivo totalmente autónomo sería bastante problemático". La IA puede encontrar señales ocultas en los datos, pero son las personas las que deben conectar los puntos.
Diagnóstico temprano
Además de predecir el curso de una epidemia, muchos confían en que la IA ayude a identificar a las personas infectadas. La tecnología tiene un buen historial en este aspecto. Los modelos de aprendizaje automático que analizan imágenes médicas son capaces de detectar señales tempranas que pasan desapercibidas ante los médicos humanos para dolencias oculares y cardíacas e incluso el cáncer. Pero estos modelos generalmente requieren muchos datos de los que deben aprender.
En las últimas semanas se han publicado varios artículos online que sugieren que el aprendizaje automático es capaz de diagnosticar el COVID-19 a partir de imágenes de TAC del tejido pulmonar si se entrena para detectar signos reveladores de la enfermedad en las imágenes. El experto en aprendizaje automático e imágenes médicas de la Universidad de Ciencias Aplicadas de Noruega Occidental en Bergen (Noruega) Alexander Selvikvåg Lundervold cree que, con el tiempo, la IA debería ser capaz de detectar las señales del COVID-19 en pacientes. Pero no está claro si el camino a seguir son los escáneres. Por ejemplo, los signos físicos de la enfermedad pueden no aparecer en las imágenes hasta algún tiempo después de la infección, por eso no se podría usar como un diagnóstico temprano.
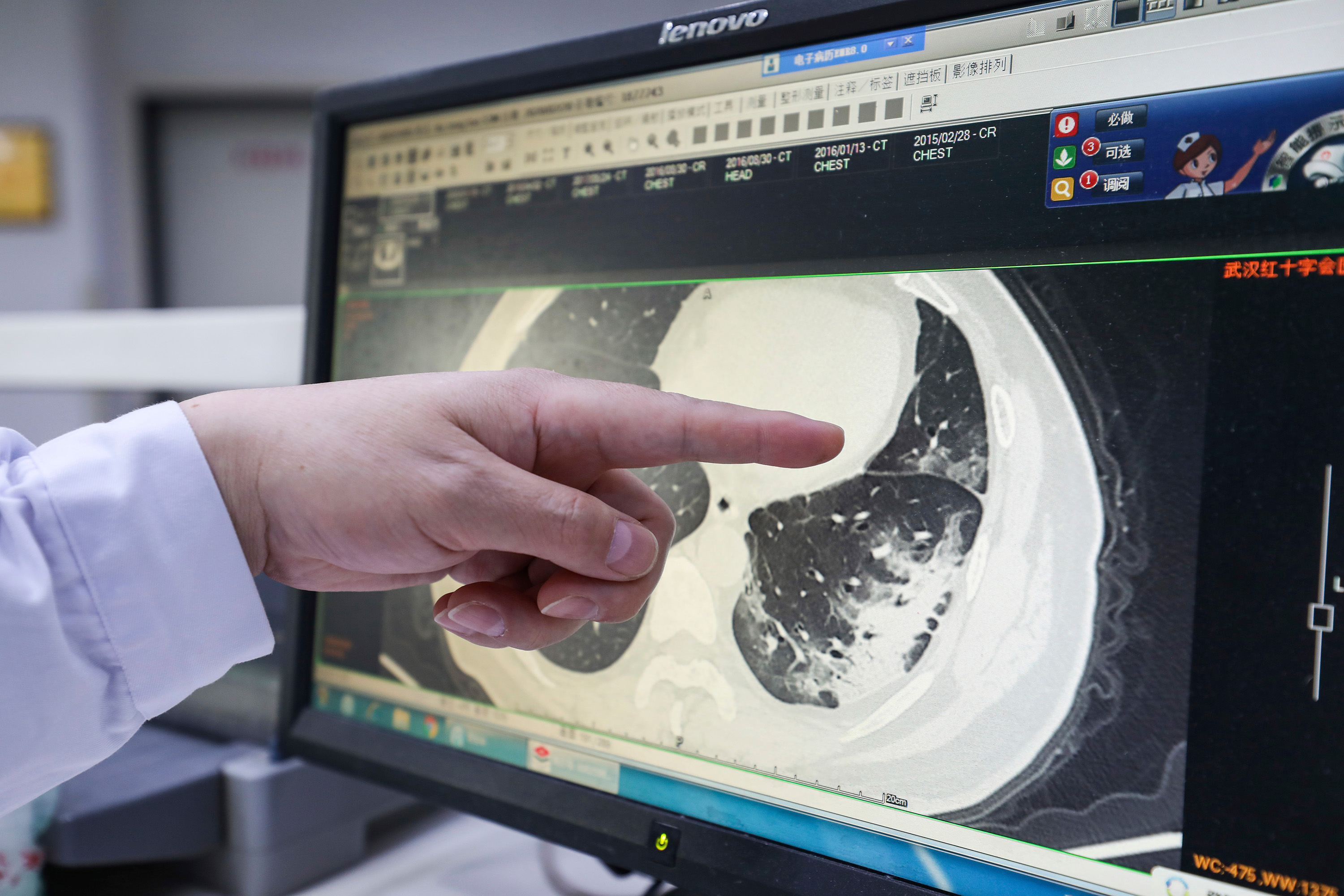
Foto: El especialista respiratorio encargado de los pacientes críticos infectados por el COVID-19 en la provincia central de Hubei (China), Fan Zhongjie, analiza una imagen de TAC. Crédito: AP Images
Además, dado que hasta el momento tenemos muy pocos datos para entrenar a los sistemas, resulta difícil calcular la precisión de los estudios publicados online. La mayoría de los sistemas de reconocimiento de imágenes, incluidos los entrenados en imágenes médicas, se adaptan a partir de los modelos entrenados por primera vez en ImageNet, un conjunto de datos ampliamente utilizado que incluye millones de imágenes cotidianas etiquetadas. "Clasificar algo simple y parecido a los datos de ImageNet, como imágenes de perros y gatos, se puede hacer con muy poca información. Pero ese no es el caso de los detalles sutiles en las imágenes médicas", explica Lundervold.
Eso no significa que vaya a ocurrir, de hecho, será posible crear herramientas de IA para detectar las primeras etapas de la infección en los futuros brotes. Pero, ahora mismo, no deberíamos creer en todas las afirmaciones de los médicos de IA que diagnostican el COVID-19.
En este escenario, la posibilidad de compartir más datos de los pacientes también resultaría útil, y lo mismo para con las técnicas de aprendizaje automático que permiten entrenar modelos cuando hay pocos datos disponibles. Entre estas técnicas destaca el "one-shot learning" (que podría traducirse como aprendizaje con un solo ejemplo, o aprendizaje único), con el cual IA es capaz de aprender patrones con solo unos pocos resultados, y el aprendizaje de transferencia, cuando una IA ya entrenada para hacer una tarea puede adaptarse rápidamente para hacer otra tarea similar, son avances prometedores, pero aún en desarrollo.
Vacuna
Los datos también son esenciales para que la IA ayude a desarrollar tratamientos para una infección. Una técnica para identificar posibles candidatos a fármacos consiste en utilizar algoritmos de diseño generativo, que producen una gran cantidad de posibles resultados. Luego, solo haría que revisarlos para quedarse solo con aquellos que habría que analizar más detalladamente. Esta técnica se puede utilizar para buscar rápidamente a través de millones de estructuras biológicas o moleculares, por ejemplo.
SRI International trabaja en una herramienta de IA de este tipo: mediante el aprendizaje profundo genera muchos nuevos candidatos a fármacos que los científicos pueden evaluar para determinar su eficacia. Esto representa una revolución en el descubrimiento de medicamentos, pero aún podrían pasar muchos meses antes de que un candidato prometedor se convierta en un tratamiento viable.
En teoría, la IA también se podría usar para predecir la evolución del coronavirus. Inam imagina algoritmos de aprendizaje no supervisado que simulen todas las posibles rutas de la evolución. Entonces se podrían añadir posibles vacunas y ver si los virus mutan para desarrollar resistencia. "Esto permitirá a los virólogos estar unos pasos por delante de los virus y crear vacunas en caso de que ocurra alguna de estas mutaciones catastróficas", explica. No cabe duda de que se trata de una posibilidad fascinante, pero también remota. Todavía no disponemos de suficiente información sobre cómo muta el virus para poder simularlo, por ahora.
Mientras tanto, el último obstáculo podrían ser los responsables políticos. Wang afirma: "Lo que más me gustaría cambiar es la opinión de los encargados de formular políticas sobre la IA". Por muchos datos que tenga, la IA no podrá predecir brotes de enfermedades por sí misma. Lograr que los líderes de gobiernos, empresas y atención médica confíen en estas herramientas cambiará fundamentalmente la rapidez con la que reaccionaríamos ante los brotes de enfermedades, asegura. Pero esa confianza debe venir de una visión realista de lo que la IA realmente es capaz de hacer en este momento, de lo que no, y de lo que podría mejorar la próxima vez.
Para que podamos sacar el máximo partido a la IA para combatir pandemias como esta, necesitaremos muchos datos, tiempo y una buena coordinación entre muchas personas diferentes. Y todo eso resulta escaso en estos momentos.
Inteligencia Artificial
La inteligencia artificial y los robots están transformando nuestra forma de trabajar y nuestro estilo de vida.
-
Minería paralela de datos, la técnica del nuevo traductor de Meta para dominar más de 100 idiomas
La aplicación presentada por Meta nos acerca a la creación de un dispositivo de traducción universal similar al Pez de Babel de La guía del autoestopista galáctico, de Douglas Adams

-
Convirtiendo los trinos en datos: esta IA estudia la migración de las aves a través del sonido
Tras décadas de frustración, las herramientas de aprendizaje automático están revelando a los ecologistas un tesoro de datos acústicos

-
Mundos virtuales generativos y modelos que "razonan": qué nos depara la IA en 2025
Ya sabemos que los agentes y los pequeños modelos lingüísticos serán las grandes tendencias del futuro. No obstante, destacamos otras cinco tendencias que deberías seguir de cerca este año
