
IBM utiliza cúbits ajustables, que son más fiables, para duplicar su volumen cuántico cada año. Por su parte, Google con sus rápidos cúbits de frecuencia fija, trabaja en la supremacía cuántica. Cada enfoque y cada compañía tiene sus propias ventajas y desventajas, y nadie sabe quién acabará ganando
El ordenador más avanzado de Google no se encuentra en la sede de la compañía en Mountain View, ni en Silicon Valley (ambas en EE. UU.). Está a unas pocas horas en coche hacia el sur, en un polígono de oficinas de una sola planta y sin mucha vida, habitado principalmente por empresas tecnológicas poco conocidas.
La diáfana oficina tiene varias docenas de puestos de trabajo. Hay un aparcamiento interior para bicicletas y otro "para tablas de surf". Las amplias puertas dobles llevan a un laboratorio del tamaño de una gran aula. Allí, en medio de ordenadores y muchos instrumentos mezclados, varios recipientes cilíndricos, cada uno un poco más grande que un barril de aceite, cuelgan de las plataformas de amortiguación de vibraciones como enormes tubos de acero.
El recipiente exterior de uno de ellos fue retirado para dejar al descubierto una maraña de varias capas de acero y latón cuyo interior se conoce como "el candelabro". Básicamente, se trata de un refrigerador superalimentado que se enfría con cada capa hacia abajo. En la parte inferior, en un espacio al vacío y a una temperatura que roza el cero absoluto (o a casi -273.15 °C), está lo que a simple vista parece un chip de silicio común. Pero en lugar de transistores, está grabado con pequeños circuitos superconductores que, a esta baja temperatura, se comportan como si átomos individuales que obedecen las leyes de la física cuántica. Cada uno de ellos es un bit cuántico, o cúbit, la unidad de almacenamiento de información básica de un ordenador cuántico.
A finales del pasado septiembre, Google anunció que uno de esos chips, llamado Sycamore, se había convertido en el primero en demostrar la "supremacía cuántica" al realizar una tarea que sería prácticamente imposible en una máquina convencional. Con solo 53 cúbits, Sycamore completó un cálculo en pocos minutos que, según Google, el actual superordenador más poderoso del mundo, el Summit, habría tardado 10.000 años en completar. Google lo presentó como un enorme avance, comparándolo con el lanzamiento del Sputnik 1 y con el primer vuelo de los hermanos Wright. Lo anunció como el inicio de una nueva era de máquinas que haría que el ordenador más poderoso de la actualidad sea visto como un simple ábaco.
En una rueda de prensa en su laboratorio cuántico, el equipo de Google respondió encantado a las preguntas de los periodistas durante casi tres horas. Pero su buen humor no podía enmascarar del todo una tensión subyacente. Dos días antes, los investigadores de IBM, el principal rival de Google en computación cuántica, habían torpedeado su gran revelación. Habían publicado un documento que básicamente acusaba a Google de haberse equivocado con sus cálculos. IBM estimaba que Summit habría tardado solo unos días replicar el trabajo de Sycamore, pero no milenios. Cuando se le preguntó qué pensaba sobre el documento de IBM, el director del equipo de Google, Hartmut Neven, evitó deliberadamente dar una respuesta directa.
¿Qué hay en un cúbit?
Al igual que en los primeros días de la informática había diferentes diseños de transistores, actualmente hay muchas formas de crear cúbits. Google e IBM utilizan una versión del mejor método, un cúbit superconductor tipo transmón, cuyo componente central es una unión de Josephson, que consiste en un par de tiras de metal superconductoras separadas por un espacio de solo un nanómetro de ancho. Los efectos cuánticos son el resultado de cómo los electrones cruzan esa brecha.
La situación se podría describir como una simple disputa académica, y en cierto sentido lo fue. Incluso si IBM tenía razón, Sycamore había hecho el cálculo 1.000 veces más rápido de lo que lo hubiera hecho Summit. Y probablemente solo harán falta unos meses para que Google construya una máquina cuántica un poco más grande capaz de demostrar su potencia sin lugar a dudas.

Sin embargo, la mayor objeción de IBM no era que el experimento de Google fue menos exitoso de lo que el gigante afirmó, sino que se trataba de una prueba que no tenía sentido en primer lugar. A diferencia de la mayoría del mundo de la computación cuántica, IBM no cree que la "supremacía cuántica" equivalga al momento de los hermanos Wright; de hecho, ni siquiera cree que vaya a haber un momento así.
El éxito que IBM persigue y al que denomina como "ventaja cuántica" es muy diferente. No se trata de una mera diferencia de palabras, ni siquiera de otra ciencia diferente, sino de una postura filosófica con raíces en la historia, la cultura y las ambiciones de IBM, y, tal vez, en el hecho de que durante ocho años sus ingresos y beneficios se ha reducido sin parar, mientras que Google y su empresa matriz Alphabet no han hecho más que crecer. Este contexto y estos diferentes objetivos podrían influir en cuál de ellas acaba primera en la carrera de la computación cuántica, si es que alguna logra terminarla.
Mundos aparte
La elegante y amplia construcción del Centro de Investigación Thomas J. Watson de IBM al norte de la ciudad de Nueva York (EE.UU.), una maestral obra neo-futurista del arquitecto finlandés Eero Saarinen, es muy diferente a las oficinas del equipo de Google. Terminado en 1961, durante la bonanza de IBM gracias a los servidores, este edificio parece a un museo, una especie de recordatorio para todos los empleados de los grandes avances logrados por la compañía, desde la geometría fractal hasta los superconductores, la inteligencia artificial (IA), y la computación cuántica.

El director del Departamento de Investigación de 4.000 personas es el español Darío Gil, cuya rápida forma de hablar intenta seguir su empeño casi evangélico. Las dos veces que hablé con él, me contó rápidamente los hitos históricos subrayando cuánto tiempo lleva IBM involucrada en la investigación relacionada con la computación cuántica (ver la cronología inferior).
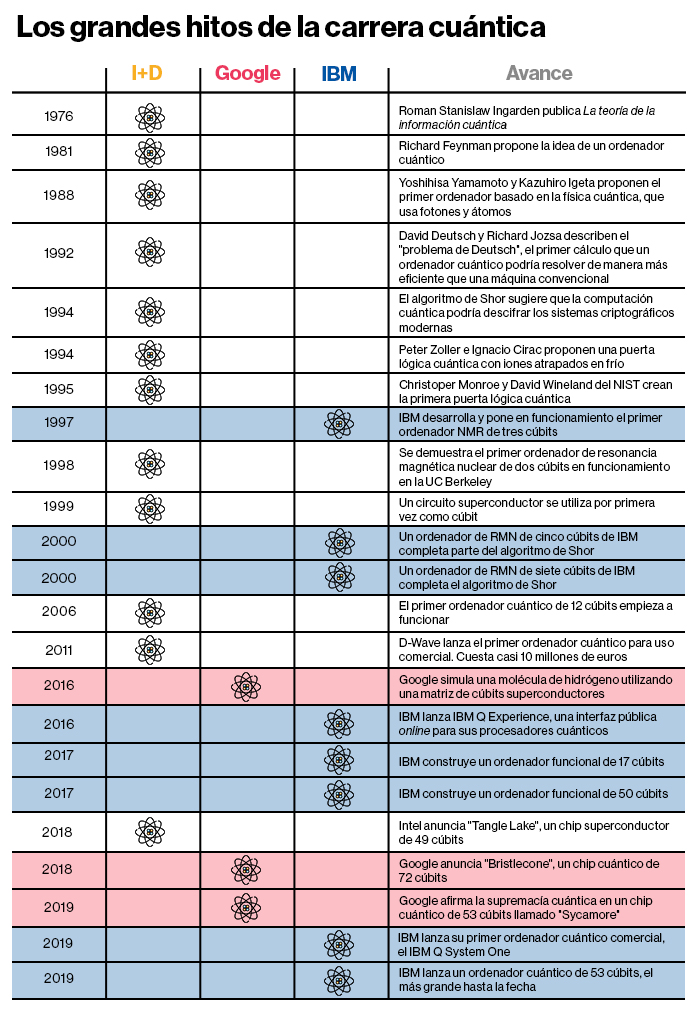
Un gran experimento: la teoría cuántica y la práctica
El componente básico de un ordenador cuántico es el bit cuántico o cúbit. En un ordenador convencional, un bit puede almacenar información en forma de ceros o de unos. Por su parte, un cúbit puede también almacenar información en un estado intermedio llamado superposición, con muchos valores diferentes. Una analogía es que si la información fuera en color, un bit clásico podría ser blanco o negro. Un cúbit en superposición podría tener cualquier color en el espectro y también podría variar en brillo.
El resultado es que un cúbit puede almacenar y procesar muchísima más información que un bit, y dicha capacidad aumenta exponencialmente a medida que aumentan los cúbits conectados. El almacenamiento de toda la información en los 53 cúbits en el chip Sycamore de Google necesitaría alrededor de 72 petabytes (72.000 millones de gigabytes) de memoria de un ordenador convencional. Con pocos cúbits más hará falta un ordenador convencional del tamaño de todo el planeta.
Pero no es sencillo. Los cúbits son delicados y muy frágiles, deben estar casi perfectamente aislados del calor, de vibraciones y de los átomos perdidos. Para cumplir esa función nacen los refrigeradores "candelabro" del laboratorio cuántico de Google. Pero incluso con ellos, solo pueden funcionar unos cientos de microsegundos como máximo antes de "colapsar" y perder su superposición.
Los ordenadores cuánticos no siempre son más rápidos que los convencionales. Simplemente son diferentes, más rápidos en algunas cosas y más lentos en otras, y requieren diferentes tipos de software. Para comparar su rendimiento, hay que escribir un programa convencional que simule al cuántico.
Para su experimento, Google eligió una prueba de evaluación comparativa llamada "muestra de circuito cuántico aleatorio". Consiste en generar millones de números aleatorios con ligeros sesgos estadísticos, que son el sello distintivo del algoritmo cuántico. Si Sycamore fuera una calculadora de bolsillo, en la prueba se hubieran presionado sus botones al azar para verificar que la pantalla mostraba los resultados esperados.
Google simuló partes de esta muestra en sus propias granjas masivas de servidores, así como en Summit, el superordenador más grande del mundo, en el Laboratorio Nacional de Oak Ridgev (EE. UU.). Los investigadores estimaron que llevar a cabo todo ese trabajo, que Sycamore realizó en 200 segundos, Summit habría tardado aproximadamente 10.000 años. ‘Voilà’: supremacía cuántica.
Entonces, ¿cuál fue la objeción de IBM? Básicamente, que hay diferentes maneras de que un ordenador convencional simule el trabajo de una máquina cuántica, y que el software escrito, la forma en la que se presentan los datos y se almacenan, y el hardware usado, influyen mucho en la rapidez de la simulación. IBM destacó que Google asumió que la simulación se tenía que dividir en muchas partes, pero Summit, con sus 280 petabytes de almacenamiento, es lo suficientemente grande como para contener el estado completo de Sycamore de forma simultánea. (IBM construyó Summit, por lo que debería saberlo).
Pero a lo largo de las décadas, la compañía se ha ganado la reputación de luchar para convertir sus proyectos de investigación en éxitos comerciales. Un ejemplo más reciente es Watson, la IA que participó en el concurso televisivo Jeopardy! y que IBM intentó convertir en un gurú médico robótico. La máquina iba a ofrecer diagnósticos e identificar tendencias en los océanos de datos médicos, pero a pesar de docenas de asociaciones con proveedores de atención médica, ha habido pocas aplicaciones comerciales, e incluso las que surgieron han mostrado resultados desiguales (ver IBM necesita una dosis de realidad sobre el potencial de Watson).
El equipo de computación cuántica, según cuenta Gil, intenta romper ese ciclo realizando la investigación y el desarrollo comercial en paralelo. Casi tan pronto como sus ordenadores cuánticos empezaron a funcionar, la compañía se puso a trabajar para hacerlos accesibles para terceros a través de la nube, donde es posible programarlos mediante una simple interfaz que funciona en un navegador web. Desde su lanzamiento en 2016 "IBM Q Experience" ya ofrece 15 ordenadores cuánticos de entre cinco y 53 cúbits. Alrededor de 12.000 personas los usan cada mes, desde investigadores académicos hasta alumnos. El uso de las máquinas más pequeñas es gratis; IBM asegura que ya tiene más de 100 clientes de pago (no quiso precisar cuántos exactamente) para usar los más grandes.
Ninguno de estos dispositivos, ni ningún otro ordenador cuántico en el mundo, salvo el Sycamore de Google, ha demostrado que puede vencer a una máquina convencional en ninguna situación. Pero esta no es la prioridad actual de IBM. Facilitar que las máquinas estén disponibles online le permite saber qué necesitarán los futuros clientes. Además, ofrece a los desarrolladores de software externos la oportunidad de aprender a escribir el código para ellos. Eso, a su vez, contribuye a su desarrollo, lo que mejorará los siguientes ordenadores cuánticos.
Este ciclo, según la compañía, es la vía más rápida para lograr su llamada ventaja cuántica, un futuro en el que los ordenadores cuánticos no necesariamente superen a los convencionales, pero sí realicen algunas cosas útiles de una forma algo más rápida o más eficiente, lo suficiente para que resulten rentables. Mientras que la supremacía cuántica es un hito único, la ventaja cuántica representa un "continuo", un mundo de posibilidades en expansión gradual, explican los representantes de IBM.
Esa sería la gran teoría unificada de Gil sobre IBM: al combinar su herencia, su experiencia técnica, la capacidad intelectual de otras personas y su dedicación a los clientes comerciales, es capaz de construir ordenadores cuánticos útiles antes y mejor que nadie.
Bajo este punto de vista, IBM cree que la demostración de supremacía cuántica de Google no fue más que "un truco de salón", según el físico de la Universidad de Texas en Austin (EE. UU.) Scott Aaronson, quien contribuyó a crear los algoritmos cuánticos que utilizó Google. Para el experto, no fue más que una llamativa distracción frente al trabajo real en el que se deberían estar centrando. Y lo peor es que resulta engañoso, porque podría provocar que la gente crea que los ordenadores cuánticos son capaces de superar a los convencionales en cualquier situación en vez de ganarlos solo en una tarea muy concreta. "'Supremacía' es una palabra que es imposible que la sociedad no la interprete mal", asegura Gil.
La opinión de Google, por supuesto, es muy diferente.
Y los intrusos aparecieron
Google era una empresa líder con ocho años de experiencia cuando empezó a abordar los problemas cuánticos en 2006, pero no formó un laboratorio cuántico hasta 2012, el mismo año en el que el físico de Caltech (EE. UU.), John Preskill, acuñó el término "supremacía cuántica".
El director de dicho laboratorio es el científico informático alemán de aspecto hípster Hartmut Neven. Lo vi una vez con un abrigo de piel azul y otra vez con un atuendo totalmente plateado en el que parecía un astronauta grunge. ("Mi esposa me compra estas cosas", me dijo). Al principio, Neven compró una máquina construida por la empresa D-Wave y pasó un tiempo tratando de alcanzar la supremacía cuántica con ella, aunque no lo consiguió. Cuenta que en 2014 convenció al entonces CEO de Google, Larry Page, para invertir en la construcción de ordenadores cuánticos. Para convencerle, le prometió que Google asumiría el desafío de Preskill. Neven recuerda: "Le dijimos: 'Escucha, Larry, volveremos en tres años y pondremos un prototipo de chip en tu mesa capaz de calcular un problema como mínimo más allá de las capacidades de las máquinas convencionales".
Como no tenían la experiencia cuántica de IBM, Google contrató a un equipo externo, dirigido por el físico de la Universidad de California en Santa Bárbara (EE. UU.) John Martinis. Su equipo y él ya se encontraban entre los mejores fabricantes de ordenadores cuánticos del mundo (habían logrado juntar hasta nueve cúbits) y para ellos la promesa de Neven a Page les parecía un objetivo válido.
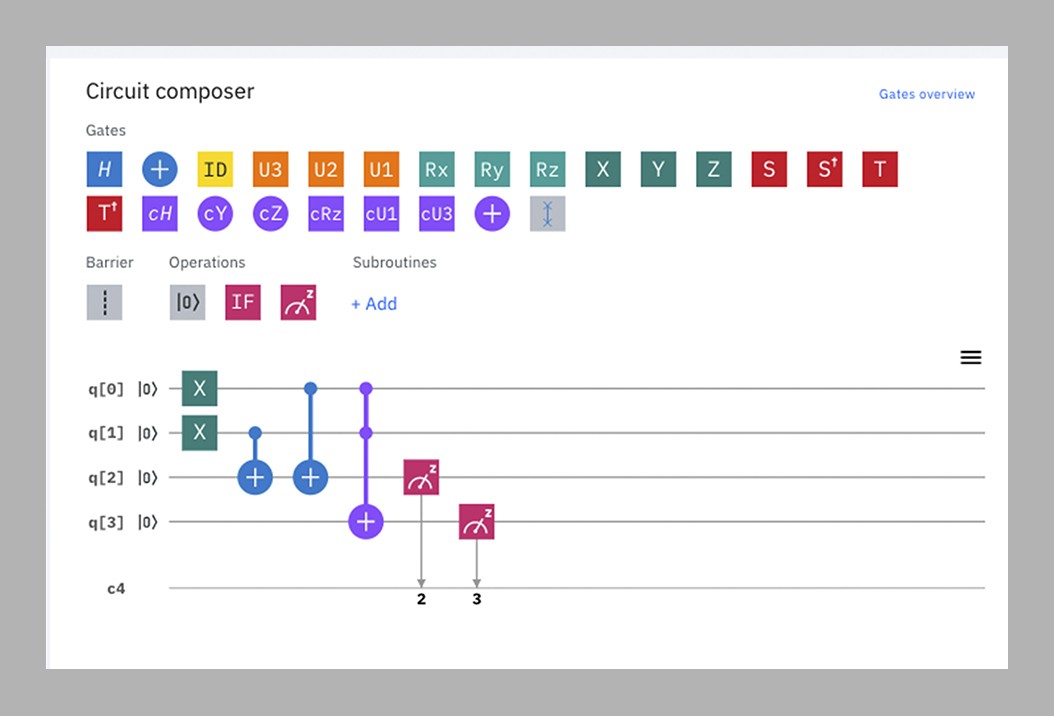
Cómo programar un ordenador cuántico
En su nivel más básico, el software de los ordenadores convencionales es una secuencia de puertas lógicas tipo NOT, OR y NAND que cambian el contenido (cero o uno) de los bits. De manera similar, el software cuántico también se estructura en forma de una serie de secuencias de puertas lógicas que actúan sobre cúbits, pero su conjunto de compuertas es más grande y más exótico, con nombres como SWAP (que intercambia los valores de dos cúbits), Pauli-X (una versión cuántica de la NOT, que invierte el valor de un cúbit), y Hadamard (que convierte un cúbit de cero o un en una superposición de cero y uno). Todavía no existen equivalentes cuánticos de los lenguajes de nivel superior como C ++ o Java, pero tanto Google como IBM han creado interfaces gráficas, como la que se muestra abajo, para facilitar la programación con las compuertas.
El plazo de tres años de Neven llegó a su fin mientras el equipo de Martinis seguía luchando por hacer un chip suficientemente grande y estable para cumplir el desafío. En 2018, Google lanzó su procesador más grande hasta la fecha, el Bristlecone. Con sus 72 cúbits, estaba muy por delante de cualquier rival. Martinis predijo que alcanzaría la supremacía cuántica ese mismo año. Pero algunos de los miembros del equipo habían trabajado en paralelo en la creación de un chip diferente, el Sycamore, que finalmente demostró ser capaz de hacer más con menos cúbits. Por lo tanto, fue un chip de 53 cúbits (inicialmente eran 54 pero uno de ellos no funcionó) el que finalmente demostró la supremacía el otoño pasado.
Para fines prácticos, el programa utilizado en esa demostración no tiene ninguna utilidad: genera números aleatorios, que no es algo para lo que se necesite un ordenador cuántico. Pero su forma de generarlos es tan particular que a un ordenador convencional le costaría muchísimo replicar, lo que sienta las bases de una prueba de concepto de supremacía cuántica.
Cuando se les pregunta a los empleados de IBM qué piensan de este logro, no dudan en mostrar su desagrado. El australiano que dirige el equipo cuántico de IBM, Jay Gambetta, responde con cautela: "No me gusta la palabra [supremacía] ni sus implicaciones". El problema, según él, consiste en que es prácticamente imposible predecir si un determinado cálculo cuántico será un reto para una máquina convencional, por lo que mostrarlo en un caso no sirve para encontrar otros casos.
Pero fuera de IBM, la gente cree que la postura del gigante de rechazar la supremacía cuántica como algo importante está al borde de la intransigencia. "Cualquiera que alguna vez tenga una oferta comercialmente relevante, primero debe mostrar su supremacía. Creo que es algo simplemente lógico", sostiene Neven. Incluso el apacible físico del MIT Will Oliver, que ha sido uno de los observadores más imparciales de esta disputa, opina: "Es un hito muy importante mostrar que un ordenador cuántico supera a uno convencional en alguna tarea, sea la que sea."
El salto cuántico
Independientemente de si estamos de acuerdo con la postura de Google o con la de IBM, para Oliver, el siguiente objetivo es claro: construir un ordenador cuántico capaz de hacer algo útil. Algún día, estas máquinas deberían poder resolver problemas que actualmente requieren cantidades imposibles de potencia de cómputo de fuerza bruta, como modelar moléculas complejas para ayudar a descubrir nuevos medicamentos y materiales, optimizar los flujos de tráfico de las ciudades en tiempo real para reducir los atascos, y hacer predicciones meteorológicas a largo plazo. (Con el tiempo, podrían ser capaces de descifrar los códigos criptográficos que se utilizan actualmente para asegurar las comunicaciones y las transacciones financieras, aunque para entonces la mayor parte del mundo probablemente habrá adoptado una criptografía resistente a los ataques cuánticos). El problema es que es casi imposible predecir cuál será la primera tarea útil, o el tamaño necesario del ordenador para realizarla.
Esa incertidumbre tiene que ver tanto con el hardware como con el software. En cuanto al hardware, Google cree que con sus diseños de chips actuales podría conseguir dispositivos con entre 100 cúbits y 1.000 cúbits. Sin embargo, igual que el rendimiento de un coche no depende únicamente del tamaño del motor, el rendimiento de un ordenador cuántico tampoco se determina simplemente por su número de cúbits. Existe una serie de factores a tener en cuenta, incluido el tiempo que se pueden mantener sin decoherencia, si son propensos a errores, lo rápido que operan y cómo es su interconexión. Esto significa que cualquier ordenador cuántico operativo actualmente solo alcanza una fracción de su potencial total.
Decoherencia
Los cúbits almacenan información de la misma manera que un tamiz almacena agua; incluso los más estables son incapaces de resistir a la "decoherencia", y sus frágiles estados cuánticos colapsan en unos pocos cientos de microsegundos. Incluso antes de eso, empiezan a acumularse los errores. Esto significa que un ordenador cuántico solo puede hacer unos pocos cálculos antes de detenerse. Los chips más grandes de Google colapsan después de 30 a 40 microsegundos, tiempo suficiente para ejecutar una secuencia de hasta 40 puertas lógicas cuánticas. Los de IBM pueden durar hasta 500 microsegundos, pero procesan las puertas más despacio (ver ‘¿Qué es un ordenador cuántico? Definición y conceptos clave’).
Mientras tanto, el software para los ordenadores cuánticos está tan poco desarrollado como los propios ordenadores. En informática convencional, los lenguajes de programación actuales han eliminado varios niveles del "código informático" que los primeros desarrolladores de software tuvieron que usar. Esto ha sido posible porque la forma de almacenar, procesar y derivar los datos ya está estandarizada. "Al programar un ordenador convencional, no hace falta saber cómo funciona un transistor", subraya el jefe del equipo de software de Google, Dave Bacon. Pero el código cuántico tiene que estar muy adaptado a los cúbits en los que se ejecutará, para aprovechar al máximo su rendimiento temperamental. Eso significa que el código para los chips de IBM no podrá ser ejecutado en máquinas de otras compañías, e incluso puede que las técnicas para optimizar el Sycamore de 53 cúbits de Google no funcionen bien en su futuro hermano de 100 cúbits. Y más importante es que eso significa que nadie puede predecir cuán difícil será la tarea que puedan abordar esos 100 cúbits.
Lo máximo que cualquiera se atreve a esperar en los próximos años es que los ordenadores cuánticos con unos pocos cientos de cúbits logren simular una estructura química medianamente compleja, a lo mejor incluso lo suficiente para avanzar en la búsqueda de un nuevo medicamento o de una batería más eficiente. No obstante, la decoherencia y los errores detendrán a todas estas máquinas antes de que puedan hacer algo realmente difícil, como descifrar la criptografía.
Para construir un ordenador cuántico con la potencia de 1.000 cúbits, hará falta un millón de cúbits actuales.
Para ello hará falta un ordenador cuántico "tolerante a fallos", capaz de compensar los errores y mantenerse en funcionamiento indefinidamente, igual que los convencionales. La solución esperada para lograrlo reside en la redundancia, es decir, conseguir que cientos de cúbits actúen como uno, en un estado cuántico compartido. Conjuntamente, podrían corregir los errores de los cúbits individuales. Y a medida que cada cúbit se rinda a la decoherencia, sus vecinos lo activarán de nuevo, en un ciclo interminable de reanimación mutua.
Se calcula que hará falta combinar hasta 1.000 cúbits para lograr ese nivel de estabilidad, lo que significa que para construir un ordenador con una potencia de 1.000 cúbits, hará falta un millón de los cúbtis actuales. Neven explica que Google estima, "de forma moderada" que podrá construir un procesador con un millón de cúbits en 10 años, aunque primero tendrá que superar grandes obstáculos técnicos, incluido uno en el que IBM aún superaría a Google.
Hasta entonces, las cosas podrían cambiar mucho. Los cúbits superconductores que Google e IBM usan actualmente podrían ser los tubos de vacío de su época y verse reemplazados por una alternativa mucho más estable y fiable. Investigadores de todo el mundo están experimentando con varios métodos para crear cúbits, aunque pocos son suficientemente avanzados para construir ordenadores funcionales. Start-ups como Rigetti, IonQ y Quantum Circuits podrían ganar ventaja con alguna técnica concreta y superar a las compañías más grandes.
Historia de dos cúbits tipo transmón
Aunque los cúbits tipo tránsmon de Google e IBM son casi idénticos, presentan una pequeña pero crucial diferencia.
Tanto en los ordenadores cuánticos de Google como de IBM, los cúbits están controlados por pulsos de microondas. Debido a los pequeños defectos de fabricación, no hay dos cúbits que respondan a pulsos de exactamente la misma frecuencia. Hay dos opciones para solucionar esto: variar la frecuencia de los pulsos para encontrar el punto óptimo de cada cúbit, como mover una llave mal hecha en una cerradura hasta que se abra; o usar campos magnéticos para "sintonizar" cada cúbit a la frecuencia correcta.
IBM usa el primer método y Google usa el segundo. Cada enfoque tiene ventajas y desventajas. Los cúbits ajustables de Google funcionan más rápido y con mayor precisión, pero son menos estables y requieren más circuitos. Los cúbits de frecuencia fija de IBM son más estables y simples, pero funcionan más despacio.
Desde un punto de vista técnico, el enfoque es casi igual, al menos en esta etapa. Sin embargo, en términos de filosofía corporativa, es la gran diferencia entre Google e IBM. Google eligió la agilidad. Neven afirma: "En general, nuestra filosofía va un poco más hacia una mayor capacidad de control a expensas de los números que la gente suele buscar". Por su parte, IBM eligió la fiabilidad. "Hay una gran diferencia entre hacer un experimento de laboratorio y publicar un estudio, y poner en marcha un sistema con, por ejemplo, un 98 % de fiabilidad y capaz funcionar todo el tiempo", explica Dario Gil.
En este momento, es Google quien lleva ventaja. No obstante, a medida que las máquinas crezcan, la ventaja puede pasar a IBM. Cada cúbit está controlado por sus propios cables individuales; un cúbit sintonizable requiere un cable extra. Determinar el cableado para miles o millones de cúbits será uno de los desafíos técnicos más difíciles a los que se enfrentan ambas compañías. IBM asegura que es una de las razones por las que eligieron el cúbit de frecuencia fija. El jefe del equipo de Google, Martinis, admite que se pasó los últimos tres años tratando de encontrar soluciones de cableado. El responsable bromea: "El problema es tan importante que hasta yo trabajé en él".

Pero dado su tamaño y recursos, tanto Google como IBM tienen posibilidades de convertirse en los actores más serios en el negocio de la computación cuántica. Las empresas alquilarán sus máquinas para abordar sus problemas igual que actualmente alquilan el almacenamiento de datos en la nube y la potencia de procesamiento de Amazon, Google, IBM y Microsoft. Y lo que empezó como una batalla entre físicos e informáticos se convertirá en una competición entre las divisiones de servicios empresariales y los departamentos de marketing.
¿Qué compañía está mejor posicionada para ganar esa competición? Con sus ingresos decrecientes, IBM podría tener más prisa que Google. Por su amarga experiencia sabe cuáles son los costes de tardar demasiado en entrar en un mercado: el verano pasado, en su mayor compra de la historia, desembolsó más de 30.000 millones de euros para adquirir Red Hat, el proveedor de servicios en la nube de código abierto, en un intento de ponerse al día con Amazon y Microsoft en ese campo y revertir su tendencia económica. Su estrategia de poner sus máquinas cuánticas en la nube y crear un negocio rentable desde el principio, parece diseñada para darle ventaja.
¿Una nueva Ley de Moore?
En lugar de contar cúbits, IBM busca lo que denomina como el "volumen cuántico", una medida de cuánta complejidad puede manejar un ordenador realmente. Su objetivo es duplicar esta medida cada año, como si fuera una versión cuántica de la famosa ley de Moore, a la que IBM ha bautizado como "ley de Gambetta", por su principal teórico cuántico, Jay Gambetta. Hasta ahora, lleva tres años cumpliéndose. Esa es la misma cantidad de datos que tenía Gordon Moore cuando postuló la ley de Moore en 1965.
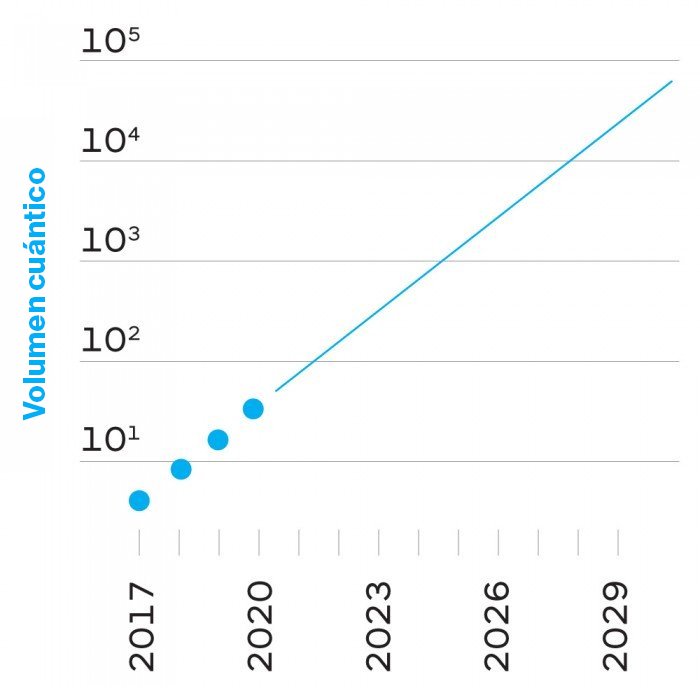
Google ha empezado a seguir el ejemplo de IBM, y entre sus clientes comerciales ya figuran el Departamento de Energía de EE. UU., Volkswagen y Daimler. La razón por la que no lo hizo antes, según Martinis, es simple: "No teníamos los recursos para ponerlo en la nube". Pero esa es otra forma de demostrar que puede permitirse el lujo de que el desarrollo empresarial no sea su prioridad.
Es demasiado pronto para saber si esa decisión da ventaja a IBM, pero probablemente lo más importante será cómo las dos compañías aplicarán sus fortalezas para abordar este problema en los próximos años. Según Gil, IBM se beneficiarán de su experiencia en crear "conjuntos de soluciones" para todo, desde la ciencia de los materiales y la fabricación de chips hasta su servicio ofrecido a grandes clientes corporativos. Por su parte, Google puede presumir de una cultura de innovación típica de Silicon Valley y mucha experiencia a la hora de escalar rápidamente sus operaciones.
En cuanto a la supremacía cuántica en sí, será un momento importante en la historia, pero eso no significa que será decisiva. Al fin y al cabo, todo el mundo recuerda el primer vuelo de los hermanos Wright, pero ¿alguien se acuerda de qué hicieron después?
Este reportaje analiza en profundidad una de nuestras 10 Tecnología Emergentes de 2020: Supremacía cuántica

Computación
Las máquinas cada vez más potentes están acelerando los avances científicos, los negocios y la vida.
-
Google anuncia un hito hacia la computación cuántica sin errores
Una técnica llamada “código de superficie” permite a los bits cuánticos de la empresa almacenar y manipular datos fielmente durante más tiempo, lo que podría allanar el camino a ordenadores cuánticos útiles

-
El vídeo es el rey: bienvenido a la era del contenido audiovisual
Cada vez aprendemos y nos comunicamos más a través de la imagen en movimiento. Esto cambiará nuestra cultura de manera inimaginable

-
Esta empresa quiere superar a Google e IBM en la carrera cuántica con un superordenador de fotones
La empresa quiere construir una computadora que contenga hasta un millón de cúbits en un campus de Chicago
