Investigadores de todo el planeta se lanzaron a desarrollar algoritmos de inteligencia artificial para diagnosticar casos o predecir su gravedad, pero dos estudios revelan que prácticamente todos tenían errores graves, principalmente por la mala calidad de los datos. Sin embargo, algunos llegaron a usarse
Cuando la pandemia de coronavirus (COVID-19) golpeó Europa en marzo de 2020, los hospitales entraron en una crisis de salud que todavía no se comprende muy bien. "Los médicos no tenían ni idea de cómo manejar a los pacientes", afirma la epidemióloga de la Universidad de Maastricht (Países Bajos) Laure Wynants, dedicada a las herramientas predictivas.
Pero estaban los datos de China, que tuvo una ventaja de cuatro meses en la carrera para vencer la pandemia. Si los algoritmos de aprendizaje automático pudieran entrenarse con esos datos para ayudar a los médicos a comprender a qué se enfrentaban y a tomar decisiones, se podrían salvar vidas. Wynants recuerda: "Pensé: 'Si hay algún momento en el que la inteligencia artificial [IA] puede demostrar su utilidad, ese momento es ahora'. Tenía muchas esperanzas".
Pero eso no ha sucedido, aunque no por falta de esfuerzo. Equipos de investigación de todo el mundo intentaron ayudar. La comunidad de IA, en particular, rápidamente se lanzó a desarrollar software que muchos creían que permitiría a los hospitales diagnosticar o clasificar a los pacientes más rápido para, en teoría, brindar el apoyo que tanto se necesitaba en la primera línea de batalla.
Al final, se desarrollaron centenares de herramientas predictivas, pero ninguna marcó una diferencia real e incluso alguna resultó potencialmente dañina.
Esa es la conclusión condenatoria de varios estudios publicados en los últimos meses. En junio, el Instituto Turing (el centro nacional de ciencia de datos e inteligencia artificial de Reino Unido) publicó un informe que resumía los debates de una serie de reuniones celebradas a finales de 2020. El consenso claro fue que las herramientas de IA habían tenido poco o ningún impacto en la lucha contra la COVID-19.
No apto para uso clínico
Es un reflejo de los resultados de dos importantes estudios que evaluaron centenares de herramientas predictivas desarrolladas el año pasado. Wynants es la autora principal de uno de ellos, publicado en el British Medical Journal, que se sigue actualizando a medida que se lanzan nuevas herramientas y se prueban las existentes. Wynants y sus colegas han analizado 232 algoritmos para diagnosticar a los pacientes o predecir la gravedad de la enfermedad que sufrían. Descubrieron que ninguno de esos algoritmos era apto para el uso clínico. Solo dos han sido señalados como suficientemente prometedores para futuras pruebas.
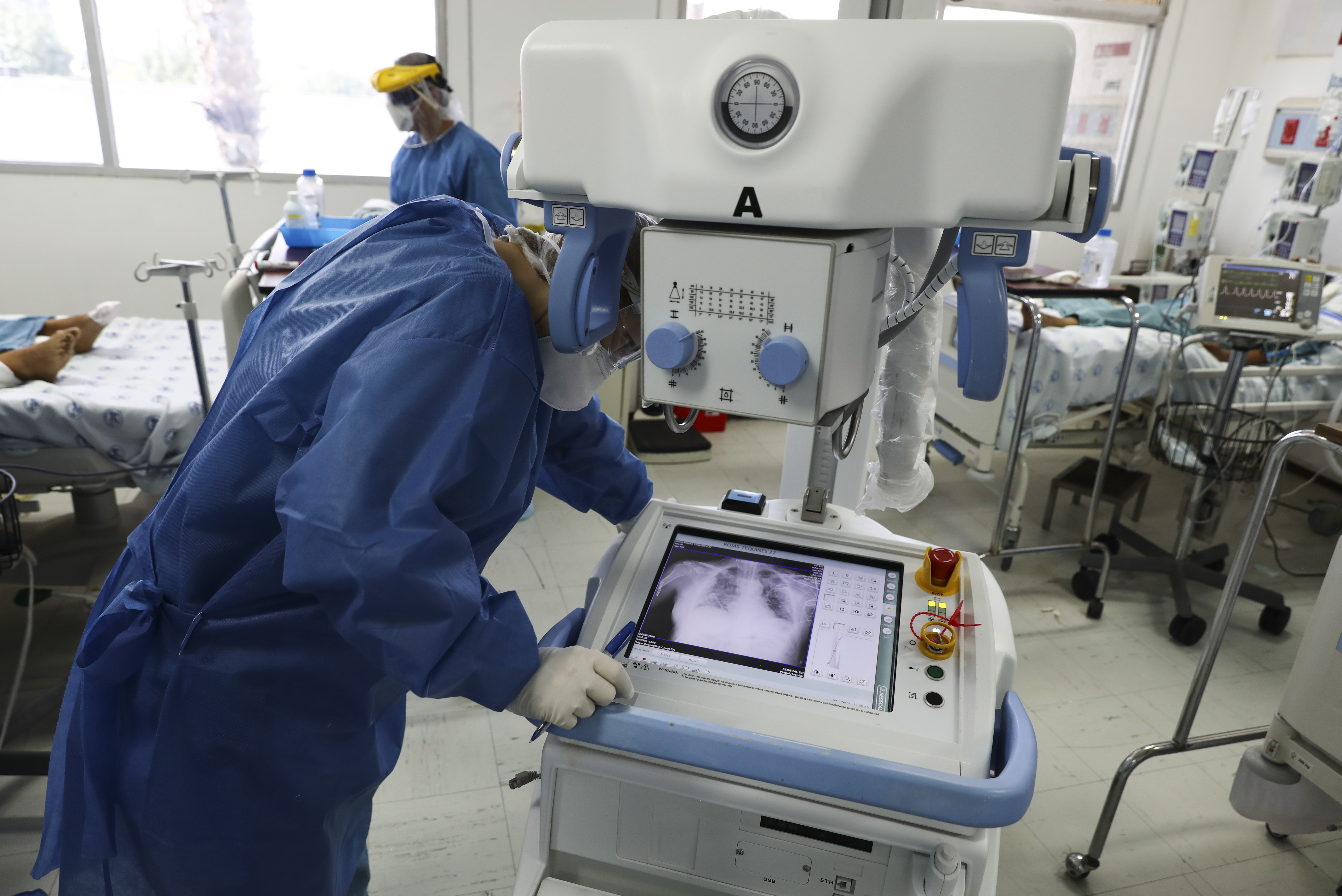
Wynants confiesa: "Resulta impactante. Yo ya tenía mis dudas antes de empezar con el estudio, pero esto superó mis temores". Su trabajo está respaldado por otro gran análisis realizado por el investigador de aprendizaje automático de la Universidad de Cambridge (EE. UU.) Derek Driggs y sus colegas, que fue publicado en Nature Machine Intelligence. Este equipo investigó los modelos de aprendizaje profundo para diagnosticar la COVID-19 y predecir el riesgo del paciente a partir de imágenes médicas, como radiografías de tórax y tomografías computarizadas (TC) de tórax. Examinaron 415 herramientas publicadas y, al igual que Wynants y sus colegas, concluyeron que ninguna era apta para el uso clínico.
Driggs, quien también trabaja en una herramienta de aprendizaje automático para ayudar a los médicos durante la pandemia, afirma: "Esta pandemia fue una gran prueba para la IA y la medicina. Hubiera sido de gran ayuda para que la sociedad estuviera de nuestro lado. Pero no creo que hayamos pasado la prueba".
Ambos equipos encontraron que los investigadores repitieron los mismos errores básicos en la forma de entrenar o probar sus herramientas. Las suposiciones incorrectas sobre los datos a menudo significaban que los modelos entrenados no funcionaban tal y como se afirmaba.
Wynants y Driggs aun creen que la IA tiene potencial de ayudar. Pero les preocupa que pudiera ser perjudicial si se construye de manera inadecuada, porque podría no detectar algunos diagnósticos o subestimar el riesgo para pacientes vulnerables. "Hay mucho bombo sobre los modelos de aprendizaje automático y sobre lo que pueden hacer hoy en día", reconoce Driggs.
Las expectativas poco realistas fomentan el uso de estas herramientas antes de que estén listas. Wynants y Driggs afirman que algunos de los algoritmos que analizaron ya se habían utilizado en hospitales y algunos incluso estaban comercializados para los desarrolladores privados. Wynants advierte: "Me temo que pueden haber dañado a los pacientes".
Entonces, ¿qué salió mal? ¿Y cómo resolver esa brecha? Lo positivo es que la pandemia ha dejado claro para muchos investigadores que la forma en la que se construyen las herramientas de IA debe cambiar. La investigadora añade: "La pandemia ha puesto de relieve los problemas que hemos estado arrastrando durante algún tiempo".
¿Qué salió mal?
Muchos de los problemas descubiertos tienen que ver con la mala calidad de los datos que los investigadores usaron para desarrollar sus herramientas. La información sobre los enfermos de COVID-19, incluidos escáneres médicos, se recopilaba y compartía durante la pandemia global, a menudo por parte de los médicos que luchaban por tratar a esos pacientes. Los investigadores querían ayudar y estos eran los únicos conjuntos de datos públicos disponibles. Pero significó que muchas herramientas se crearon utilizando datos mal etiquetados o de fuentes desconocidas.
Driggs destaca el problema de lo que él llama conjuntos de datos de Frankenstein, que se recogen de múltiples fuentes y pueden contener duplicados. Esto significa que algunas herramientas acaban siendo probadas con los mismos datos con los que fueron entrenadas, lo que las hace parecer más precisas de lo que realmente son.
También enturbia el origen de ciertos conjuntos de datos. Esto puede provocar que los investigadores no detecten algunos puntos importantes que sesgan el entrenamiento de sus modelos. Muchos, sin saberlo, utilizaron un conjunto de datos que contenía escáneres de tórax de niños que no tenían COVID-19 como ejemplos de cómo se veían los casos sin COVID-19. Pero como resultado, las IA aprendieron a identificar a los niños, no a la COVID-19.
El grupo de Driggs entrenó su propio modelo utilizando un conjunto de datos que contenía una combinación de exploraciones tomadas cuando los pacientes estaban acostados y de pie. Como los pacientes escaneados acostados tenían más probabilidades de estar gravemente enfermos, la IA aprendió erróneamente a predecir el riesgo de la COVID-19 grave en función de la posición en la que se encontraba la persona.
En otros casos, se descubrió que algunas IA detectaban la fuente del texto que ciertos hospitales usaban para etiquetar los escaneos. Como resultado, las fuentes de los hospitales con casos más graves se convirtieron en los predictores del riesgo de la COVID-19.
Errores como estos parecen obvios en retrospectiva. También se pueden corregir ajustando los modelos, si los investigadores los detectan. Se pueden reconocer las deficiencias y publicar un modelo menos preciso y también menos engañoso. Pero muchas herramientas fueron desarrolladas por investigadores de IA que carecían de la experiencia médica para detectar los errores en los datos o por investigadores médicos que carecían de las habilidades matemáticas para eliminar esos errores.
Un problema más sutil que Driggs destaca es el sesgo incorporado, o el sesgo introducido en el punto en el que se etiqueta un conjunto de datos. Por ejemplo, muchas imágenes médicas se etiquetaban en función de si los radiólogos que las hacían señalaban la presencia de la COVID-19. Pero eso incrusta, o incorpora, cualquier sesgo de ese médico concreto en la verdad básica de un conjunto de datos. Sería mucho mejor etiquetar una imagen médica con el resultado de una prueba de PCR en vez de la opinión de un médico, resalta Driggs. Pero no siempre hay tiempo para los detalles estadísticos en hospitales tan ocupados.
Eso no ha impedido que algunas de estas herramientas se introduzcan rápidamente en la práctica clínica. Wynants explica que no se sabe claramente cuáles se utilizan ni cómo. Los hospitales a veces afirman que usan una herramienta solo con fines de investigación, lo que dificulta evaluar cuánto confían en ellas los médicos. "Hay mucho secretismo", resalta Wynants.
Le pidió a una empresa que comercializaba sus algoritmos de aprendizaje profundo que compartiera información sobre su método, pero no recibió ninguna respuesta. Posteriormente encontró varios modelos publicados por investigadores vinculados a esta empresa, todos con un alto riesgo de sesgo. "En realidad, no sabemos qué implementó la empresa", señala.
En su opinión, algunos hospitales incluso han firmado acuerdos de no divulgación con sus proveedores de IA médica. Cuando les preguntaba a los médicos qué algoritmos o software usaban, a veces le respondían que no se les permitía decirlo.
Cómo arreglarlo
¿Cuál es la solución? Mejores datos ayudarían, pero en tiempos de crisis es mucho pedir. Resulta más importante aprovechar al máximo los conjuntos de datos que ya tenemos. Lo más sencillo sería que los equipos de inteligencia artificial colaboraran más con los médicos, opina Driggs. Los investigadores también deberían compartir sus modelos y revelar cómo fueron entrenados para que otros puedan probarlos y desarrollarlos. Y añade: "Esas dos cosas las podríamos hacer ya. Y resolverían quizás el 50 % de los problemas que hemos identificado".
También sería más fácil obtener datos si los formatos estuvieran estandarizados, destaca el médico que dirige el equipo de tecnología clínica en la organización benéfica de investigación de salud global Wellcome Trust, Bilal Mateen, con sede en Londres (Reino Unido).
Otro problema que Wynants, Driggs y Mateen identifican es que la mayoría de los investigadores se apresuraron a desarrollar sus propios modelos, en vez colaborar o mejorar los existentes. El resultado fue que el esfuerzo colectivo mundial produjo centenares de herramientas mediocres, en lugar de un puñado de herramientas adecuadamente entrenadas y probadas.
Wynants detalla: "Los modelos son muy similares, casi todos usan las mismas técnicas con pequeños ajustes, los mismos datos y todos cometen los mismos errores. Si todas estas personas que fabrican nuevos modelos probaran los modelos ya disponibles, tal vez a estas alturas tendríamos algo que sí podría ayudar en la parte clínica".
En cierto sentido, este es un viejo problema de la investigación. Los investigadores académicos tienen pocos incentivos profesionales para compartir los trabajos o validar los resultados existentes. No hay recompensas por avanzar para llevar la tecnología de "la mesa del laboratorio a la cabecera", considera Mateen.
Para abordar este problema, la Organización Mundial de la Salud está pensando en un acuerdo de intercambio de datos de emergencia que se pondría en marcha durante las crisis sanitarias internacionales. Permitiría a los investigadores intercambiar los datos a través de las fronteras con mayor facilidad, subraya Mateen. Antes de la cumbre del G7 en Reino Unido en junio, los principales grupos científicos de las naciones participantes también pidieron "disponibilidad de datos" para prepararse para futuras emergencias sanitarias.
Estas iniciativas suenan un poco vagas y los llamamientos al cambio siempre recuerdan a ilusiones. Pero Mateen tiene una visión que él llama "ingenuamente optimista". Antes de la pandemia, el impulso de tales iniciativas se había estancado. "Parecía que se trataba de una montaña demasiado alta, cuya vista no valía la pena. La COVID-19 ha vuelto a poner mucho de esto en la agenda", resalta.
Y concluye: "Hasta que no aceptemos la idea de que tenemos que resolver los problemas poco atractivos antes que los más atractivos, estamos condenados a repetir los mismos errores. Sería inaceptable si no sucediera. Olvidar las lecciones de esta pandemia es una falta de respeto hacia los que fallecieron".
Inteligencia Artificial
La inteligencia artificial y los robots están transformando nuestra forma de trabajar y nuestro estilo de vida.
-
Al habla con la IA: el reto de lograr voces más diversas e inclusivas
La iniciativa Common Voice, de Mozilla, busca que las voces generadas por inteligencias artificiales sean más inclusivas y reflejen una mayor variedad de dialectos para asegurar que las particularidades de cada lugar y cultura se preserven frente al avance tecnológico

-
Estos robots aprendieron a superar obstáculos reales desde un entorno virtual gracias a la IA
Un nuevo sistema podría ayudar a entrenar robots usando exclusivamente mundos generados mediante inteligencia artificial

-
Por qué la IA podría comerle la tostada a la computación cuántica
Los rápidos avances en la aplicación de la inteligencia artificial a las simulaciones físicas y químicas hacen que algunos se pregunten si de verdad necesitamos ordenadores cuánticos
