
A pesar de los enormes avances en inteligencia artificial, las máquinas parlantes hablan fatal. Esto se debe al tipo de información de entrenamiento que utilizan. Para solucionarlo, un equipo ha usado los espectrogramas para crear una inteligencia artificial capaz de copiar cualquier voz
La forma de hablar de las máquinas suele resultar bastante decepcionante. Hasta los mejores sistemas de conversión de texto a voz suenan muy mecánicos y carecen de los cambios de entonación básicos caracterizan a las personas. El tan famoso sistema de voz de Stephen Hawking es un buen ejemplo.
Si se tienen en cuenta los enormes avances en aprendizaje automático e inteligencia artificial (IA) de los últimos años, la mala calidad de las máquinas parlantes actuales resulta chocante. Las técnicas que han funcionado tan bien a la hora de reconocer caras y objetos, las que son capaces de producir imágenes realistas deberían funcionar igualmente bien con el audio. Pero la realidad no es así.
Al menos hasta ahora. Los investigadores de Facebook AI Research Sean Vasquez y Mike Lewis, han encontrado una manera de superar las limitaciones de los sistemas de conversión de texto a voz para producir clips de audio increíblemente realistas y generados completamente por un ordenador. Su máquina, llamada MelNet, no solo reproduce la entonación humana, también puede imitar la voz de personas reales. Así que el equipo lo entrenó para hablar como Bill Gates, entre otros. El trabajo nos permitiría interactuar de forma más realista con los ordenadores, pero también abre la puerta a un nuevo tipo de noticias falsas basadas en audios.
Primero algunos antecedentes. El lento progreso en los sistemas realistas de conversión de texto a voz no se debe a la falta de trabajo. Numerosos equipos han intentado entrenar algoritmos de aprendizaje profundo para reproducir patrones de voz realistas con grandes bases de datos de audio.
El problema de este enfoque se basa en el tipo de datos empleados, opinan Vásquez y Lewis. Hasta ahora, la mayoría del trabajo se ha centrado en grabaciones de audio en forma de onda que muestran cómo la amplitud del sonido cambia con el tiempo, y cada segundo de audio grabado consta de decenas de miles de pasos de tiempo.
Estas formas de onda muestran patrones específicos en varias escalas diferentes. Durante unos pocos segundos de habla, por ejemplo, la forma de onda refleja los patrones característicos asociados a las secuencias de las palabras. Pero en la escala de microsegundos, la forma de onda muestra características asociadas al tono y el timbre de la voz. Y en otras escalas, la forma de onda refleja la entonación del hablante, la estructura del fonema, etcétera. Otra forma de definir estos patrones consiste en analizar las correlaciones entre la forma de onda en un paso de tiempo y en el siguiente. Entonces, para una escala de tiempo dada, el sonido al inicio de una palabra se puede correlacionar con los sonidos que siguen.
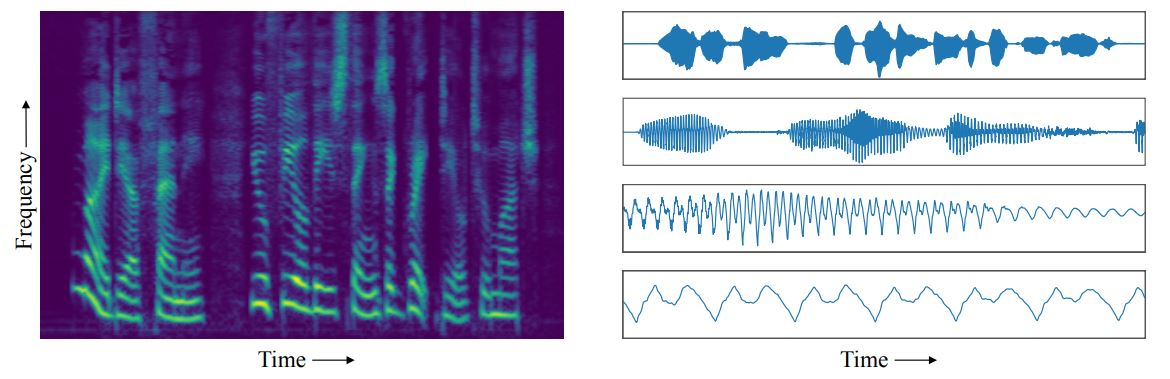
Los sistemas de aprendizaje profundo suelen aprender y reproducir bien este tipo de correlaciones. El problema es que las correlaciones actúan en diferentes escalas de tiempo, y los sistemas de aprendizaje profundo solo pueden estudiar las correlaciones en escalas de tiempo limitadas. Esto se debe a un tipo de proceso de aprendizaje que emplean, llamado retropopagación, que reconfigura la red repetidamente para mejorar su rendimiento sobre la base de los ejemplos que detecta.
La repetición limita la escala de tiempo en la que se pueden aprender las correlaciones. Por lo tanto, una red de aprendizaje profundo puede aprender correlaciones en formas de onda de audio en escalas de tiempo largas o cortas, pero no en ambas. Esa es la razón por la que se les da tan mal reproducir un discurso.
Así que Vásquez y Lewis proponen un enfoque diferente. En lugar de formas de ondas de audio, han entrenado a su red de aprendizaje profundo con espectrogramas. Los espectrogramas graban todo el espectro de frecuencias de audio y su variación a lo largo del tiempo. Entonces, mientras que las formas de onda capturan el cambio en el tiempo de un parámetro, la amplitud, los espectrogramas capturan el cambio en un amplio rango de diferentes frecuencias.
Esto significa que este tipo de representación de datos incluye mucha más información sobre el audio. La investigación explica: "El eje temporal de un espectrograma es varios órdenes de magnitud más compacto que el de una forma de onda, es decir, decenas de miles de pasos de tiempo en las formas de onda corresponden a cientos de pasos de tiempo en espectrogramas".
Eso hace que las correlaciones sean más accesibles para un sistema de aprendizaje profundo. El artículo continúa: "Esto permite que nuestros modelos de espectrograma generen muestras de voz y música incondicionales con consistencia durante varios segundos".
Y los resultados son impresionantes. Al entrenar el sistema con discursos de charlas TED, MelNet puede reproducir la voz del conferenciante y decir casi cualquier cosa durante unos pocos segundos. Los investigadores de Facebook han demostrado la flexibilidad de MelNet con la charla TED de Bill Gates. Tras el entrenamiento, el sistema es capaz de decir una serie de frases aleatorias con la voz del magnate.
Este es el sistema que dice que "fruncimos el ceño cuando las cosas no van bien" y que "Oporto es un vino fuerte con un sabor ahumado". Puede escuchar otros ejemplos aquí.
"Fruncimos el ceño cuando las cosas no van bien".
"Oporto es un vino fuerte con un sabor ahumado".
Por supuesto, MelNet tiene algunas limitaciones. El habla humana contiene correlaciones incluso en escalas de tiempo más largas. Por ejemplo, los humanos usan diferente entonación para indicar cambios en el tema o en el estado de ánimo, mientras que las historias se desarrollan en decenas de segundos o minutos. La máquina de Facebook todavía no parece capaz de hacer eso. Así que, aunque MelNet puede crear expresiones extraordinariamente realistas, el equipo aún no ha perfeccionado la pronunciación de frases más largas, párrafos o historias completas. Y no parece que vayan a conseguirlo dentro de poco.
Sin embargo, el trabajo podría tener un gran impacto en la interacción humano-máquina. Muchas conversaciones se basan únicamente en frases cortas. Los operadores de telefonía y los servicios de asistencia en particular pueden funcionar con un rango de frases relativamente cortas. Esta tecnología podría automatizar estas interacciones de una manera mucho más humana que los sistemas actuales. Por el momento, Vásquez y Lewis no han mencionado sus posibles aplicaciones.
Y como siempre, existen los posibles problemas éticos de las máquinas con sonido natural, particularmente aquellas capaces de imitar a los humanos de manera tan fiel. No hace falta pensar mucho para imaginar escenarios en los que la tecnología se pueda usar para hacer daño. Y por esa razón, se trata de otro avance de IA que plantea más preguntas éticas que respuestas.
Ref: arxiv.org/abs/1906.01083: MelNet: A Generative Model for Audio in the Frequency Domain
Inteligencia Artificial
La inteligencia artificial y los robots están transformando nuestra forma de trabajar y nuestro estilo de vida.
-
La "sustancia" del algoritmo: la IA cada vez está más cerca de actuar por nosotros
En un futuro cercano, la IA no solo será capaz de imitar nuestra personalidad, sino también de actuar en nuestro nombre para llevar a cabo tareas humanas. Sin embargo, esto da lugar a nuevos dilemas éticos que aún deben ser resueltos

-
Por qué medir la IA sigue siendo un desafío pendiente
Los benchmarks, diseñados para evaluar el rendimiento de una IA, a menudo están basados en criterios opacos o en parámetros que no reflejan su impacto real. No obstante, hay enfoques que buscan ofrecer evaluaciones más precisas y alineadas con desafíos prácticos

-
Qué es el 'red-teaming', el proceso que permite a OpenAI detectar fallos en ChatGPT
A través del red-teaming, un proceso en el que se simulan ataques para buscar fallos en los sistemas, OpenAI identifica vulnerabilidades en sus herramientas. Sin embargo, la amplia variedad de situaciones en las que se pueden utilizar estos modelos dificulta su control
