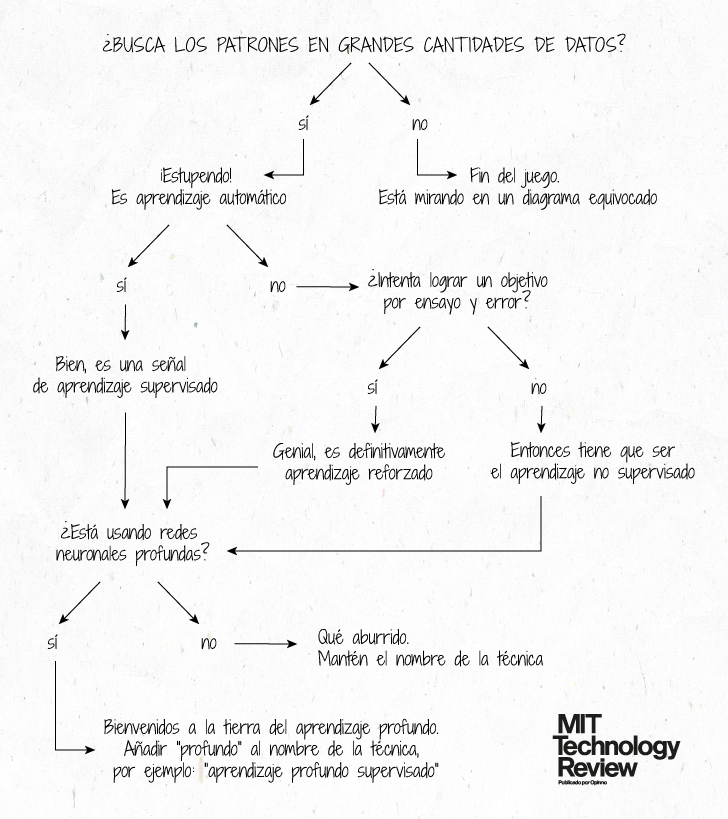
Netflix, Facebook o Google utilizan algoritmos de aprendizaje automático para mostrar los contenidos que más pueden interesarle. Pero, ¿cómo funcionan exactamente estos sistemas de inteligencia artificial? Descubra los detalles del proceso por el que encuentran patrones en grandes cantidades de datos
La gran mayoría de los avances y aplicaciones de inteligencia artificial (IA) de los que se habla se refieren a una categoría de algoritmos conocida como aprendizaje automático. Para obtener más información sobre la IA, consulte nuestro primer diagrama de flujo (ver ¿Cómo saber si está usando una IA? Descúbralo con este gráfico).
Los algoritmos de aprendizaje automático utilizan estadísticas para encontrar patrones en grandes cantidades de datos (técnicamente, existen formas de realizar aprendizaje automático en pequeñas cantidades de datos, pero generalmente se necesitan enormes cantidades para conseguir buenos resultados). Y por datos entendemos diferentes cosas (números, palabras, imágenes, clics, etc.). Si algo se puede almacenar digitalmente, es posible incorporarlo un algoritmo de aprendizaje automático.
El aprendizaje automático es el proceso que alimenta muchos de los servicios que utilizamos hoy en día: los sistemas de recomendación de Netflix, YouTube y Spotify, los buscadores como Google y Baidu, las redes sociales de noticias como Facebook y Twitter, los asistentes de voz como Siri y Alexa... Y la lista continúa.
En todos estos casos, cada plataforma recopila la mayor posible cantidad de información sobre nosotros: los géneros que nos gustan, los enlaces en los que entramos, las publicaciones a las que reaccionamos... y utiliza el aprendizaje automático para hacer una suposición muy fundamentada sobre lo que nos podría seguir gustando de ahí en adelante. O, en el caso de un asistente de voz, sobre qué palabras coinciden mejor con los divertidos sonidos que salen de nuestra boca.
Francamente, este proceso es bastante básico: encontrar el patrón y aplicarlo. Pero prácticamente domina el mundo. Eso es en gran parte gracias a un invento de 1986 del que hoy se conoce como el padre del aprendizaje profundo, Geoffrey Hinton (ver El hallazgo de hace 30 años en el que se basa toda la inteligencia artificial actual).
El aprendizaje profundo es el aprendizaje automático con esteroides: utiliza una técnica que les ofrece a las máquinas una mayor capacidad para encontrar (y amplificar) incluso los patrones más pequeños. Esta técnica se basa en redes neuronales profundas. El apellido de profundas se debe a que tienen muchísimas capas de nodos de cálculos simples que trabajan en conjunto para buscar datos y entregar un resultado final en forma de predicción.
Las redes neuronales se inspiraron ligeramente en el funcionamiento interno del cerebro humano. Los nodos son como neuronas y la red es como el cerebro mismo. (Para los investigadores que se avergüenzan de esta comparación: dejen de desdeñar la analogía. Es una buena analogía.) Pero Hinton publicó su descubrimiento en un momento en el que las redes neuronales estaban perdiendo aceptación. Nadie sabía realmente cómo entrenarlas, y por eso no estaban dando buenos resultados. La técnica tardó casi 30 años en volver a la escena. Y la verdad es que hizo una buena reaparición.
Una última cosa que hay que saber es que el aprendizaje automático (y profundo) presenta tres variedades diferentes: supervisado, no supervisado y reforzado.
-
En el aprendizaje supervisado, que es el más frecuente, los datos están etiquetados para indicar a la máquina exactamente qué patrones debe buscar. Piense en ello como si fuera un perro rastreador que, una vez que sepa el olor que debe buscar, perseguirá el objetivo deseado. Eso es lo que pasa cuando le damos al play en un programa de Netflix: le estamos diciendo al algoritmo que encuentre otros programas similares.
-
En el aprendizaje no supervisado, los datos no llevan etiquetas. La máquina busca sola cualquier patrón que pueda encontrar. Es como dejar que un perro huela toneladas de objetos diferentes y que los clasifique en grupos con olores similares. Las técnicas no supervisadas no son tan populares porque tienen aplicaciones menos visibles. Curiosamente, han ganado terreno en la ciberseguridad (ver Más el 50% de las empresas podrían ser víctimas del criptohackeo).
-
Por último, tenemos el aprendizaje por refuerzo o reforzado, la última frontera del aprendizaje automático. Un algoritmo reforzado aprende por ensayo y error para lograr un objetivo claro. Prueba muchas cosas diferentes y es recompensado o penalizado dependiendo de si sus comportamientos ayudan o impiden alcanzar su objetivo. Esto es como dar y retener un premio cuando se le enseña a un perro un nuevo truco. El aprendizaje reforzado es la base de AlphaGo de Google, el programa que supera a los mejores jugadores humanos en el complejo juego de Go.
Eso es todo. Ahora, el diagrama de flujo del comienzo del artículo le ayudará a tener un resumen final.
Inteligencia Artificial
La inteligencia artificial y los robots están transformando nuestra forma de trabajar y nuestro estilo de vida.
-
De predicar el pastafarismo a votar leyes: el experimento en Minecraft que creó una sociedad propia con IA
Un experimento en Minecraft con personajes impulsados por IA demostró que, de manera autónoma, pueden desarrollar comportamientos similares a los humanos, como hacer amigos, inventar roles laborales o incluso difundir una religión como el pastafarismo entre sus compañeros para ganar adeptos

-
La "sustancia" del algoritmo: la IA cada vez está más cerca de actuar por nosotros
En un futuro cercano, la IA no solo será capaz de imitar nuestra personalidad, sino también de actuar en nuestro nombre para llevar a cabo tareas humanas. Sin embargo, esto da lugar a nuevos dilemas éticos que aún deben ser resueltos

-
Por qué medir la IA sigue siendo un desafío pendiente
Los benchmarks, diseñados para evaluar el rendimiento de una IA, a menudo están basados en criterios opacos o en parámetros que no reflejan su impacto real. No obstante, hay enfoques que buscan ofrecer evaluaciones más precisas y alineadas con desafíos prácticos
